Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Hugging Face AutoTrain est un outil no-code permettant d’entraîner des modèles de pointe pour des tâches de traitement du langage naturel (NLP), de vision par ordinateur (CV), de parole, et même pour des tâches tabulaires.
W&B est directement intégré à Hugging Face AutoTrain et fournit le suivi des expériences ainsi que la gestion de la configuration. Il vous suffit d’utiliser un seul paramètre dans la commande CLI pour vos expériences.
Installez autotrain-advanced et wandb.
Ligne de commande
Notebook
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
pass@1 sur les benchmarks GSM8k.
Préparez le jeu de données
-
Votre fichier d’entraînement doit contenir une colonne
text, utilisée pour l’entraînement. Pour de meilleurs résultats, les données de la colonne text doivent respecter le format ### Human: Question?### Assistant: Answer.. Consultez un excellent exemple dans timdettmers/openassistant-guanaco.
Cependant, le jeu de données MetaMathQA contient les colonnes query, response et type. Commencez par prétraiter ce jeu de données. Supprimez la colonne type et fusionnez le contenu des colonnes query et response dans une nouvelle colonne text, au format ### Human: Query?### Assistant: Response.. Le jeu de données obtenu, rishiraj/guanaco-style-metamath, est ensuite utilisé pour l’entraînement.
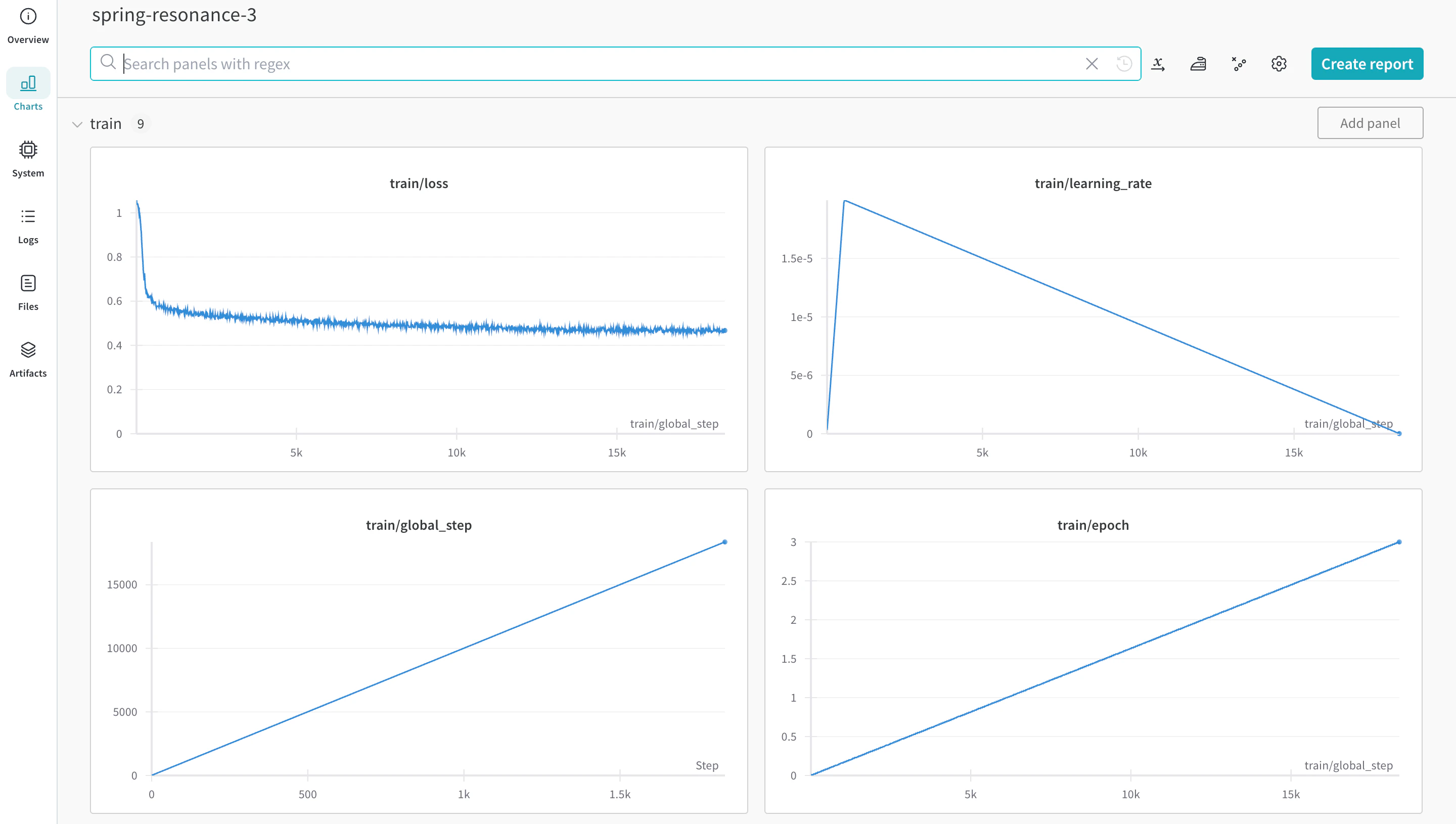
Vous pouvez démarrer l’entraînement avec autotrain advanced depuis la ligne de commande ou un notebook. Utilisez l’argument --log, ou --log wandb pour enregistrer vos résultats dans un Run W&B.
Ligne de commande
Notebook
autotrain llm \
--train \
--model HuggingFaceH4/zephyr-7b-alpha \
--project-name zephyr-math \
--log wandb \
--data-path data/ \
--text-column text \
--lr 2e-5 \
--batch-size 4 \
--epochs 3 \
--block-size 1024 \
--warmup-ratio 0.03 \
--lora-r 16 \
--lora-alpha 32 \
--lora-dropout 0.05 \
--weight-decay 0.0 \
--gradient-accumulation 4 \
--logging_steps 10 \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token <huggingface-token> \
--repo-id <huggingface-repository-address>
# Définir les hyperparamètres
learning_rate = 2e-5
num_epochs = 3
batch_size = 4
block_size = 1024
trainer = "sft"
warmup_ratio = 0.03
weight_decay = 0.
gradient_accumulation = 4
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
logging_steps = 10
# Exécuter l’entraînement
!autotrain llm \
--train \
--model "HuggingFaceH4/zephyr-7b-alpha" \
--project-name "zephyr-math" \
--log "wandb" \
--data-path data/ \
--text-column text \
--lr str(learning_rate) \
--batch-size str(batch_size) \
--epochs str(num_epochs) \
--block-size str(block_size) \
--warmup-ratio str(warmup_ratio) \
--lora-r str(lora_r) \
--lora-alpha str(lora_alpha) \
--lora-dropout str(lora_dropout) \
--weight-decay str(weight_decay) \
--gradient-accumulation str(gradient_accumulation) \
--logging-steps str(logging_steps) \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token str(hf_token) \
--repo-id "rishiraj/zephyr-math"