Déployez un artifact de modèle depuis W&B vers NVIDIA NeMo Inference Microservice. Pour ce faire, utilisez W&B Launch. W&B Launch convertit les artifacts de modèle au format NVIDIA NeMo Model, puis les déploie sur un serveur NIM/Triton en cours d’exécution. W&B Launch prend actuellement en charge les types de modèles compatibles suivants :Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Le temps de déploiement varie selon le modèle et le type de machine. La configuration de base de Llama2-7b prend environ 1 minute sur l’instance Google Cloud
a2-ultragpu-1g.Démarrage rapide
-
Créez une Launch queue si vous n’en avez pas déjà une. Voir un exemple de configuration de file d’attente ci-dessous.
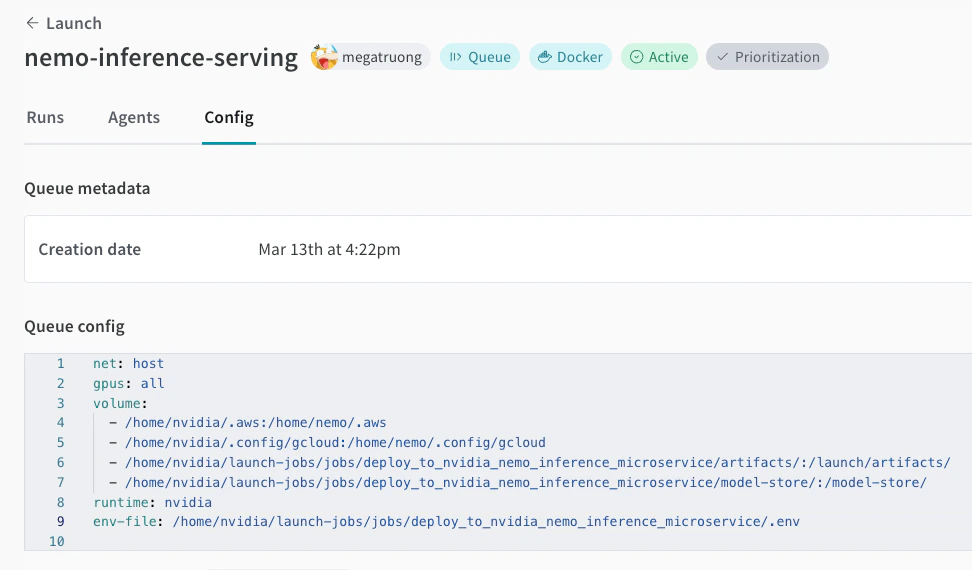
-
Créez ce job dans votre projet :
-
Lancez un agent sur votre machine équipée d’un GPU :
-
Soumettez le launch job de déploiement avec les configurations souhaitées depuis la Launch UI
- Vous pouvez aussi le soumettre via la CLI :
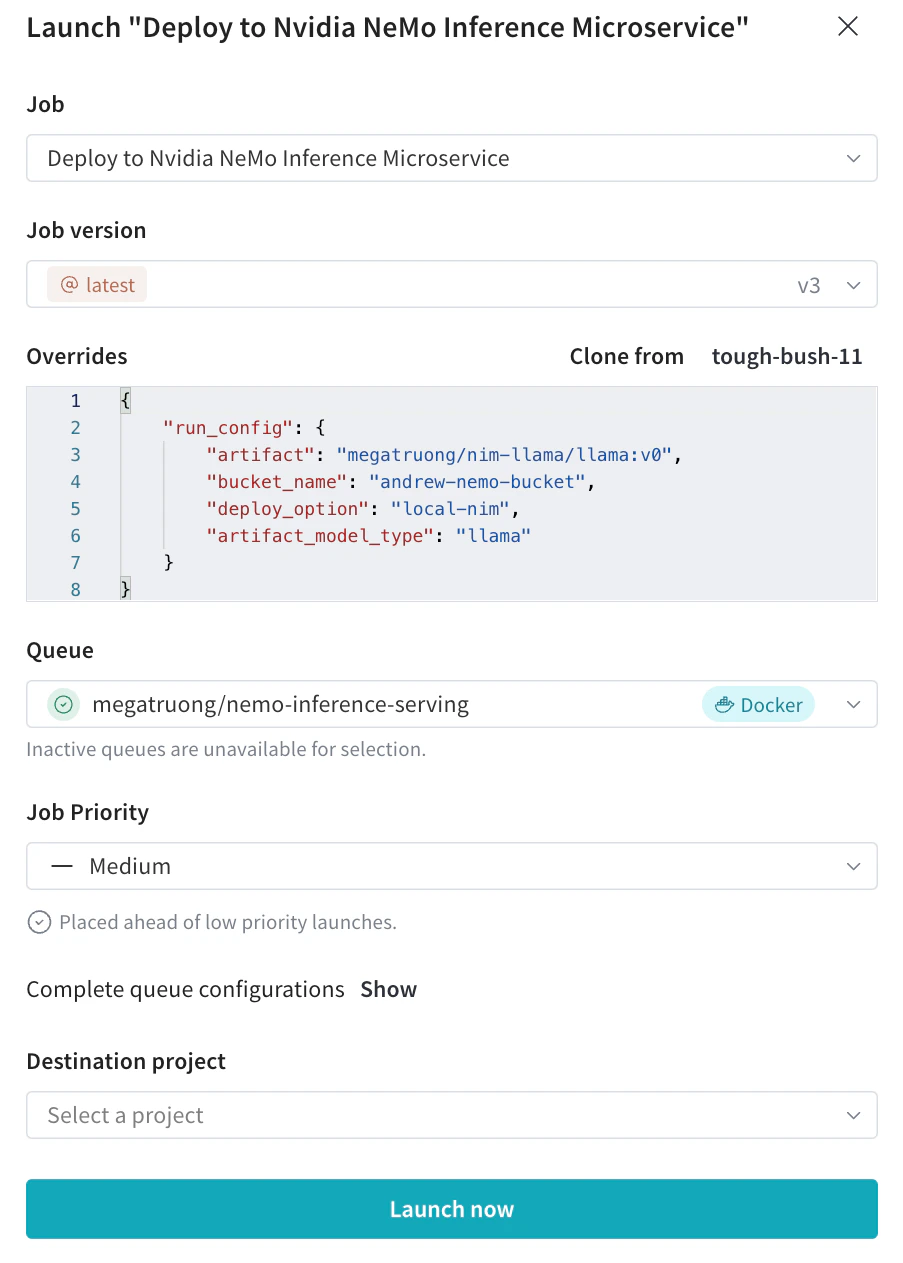
- Vous pouvez aussi le soumettre via la CLI :
-
Vous pouvez suivre le processus de déploiement dans la Launch UI.
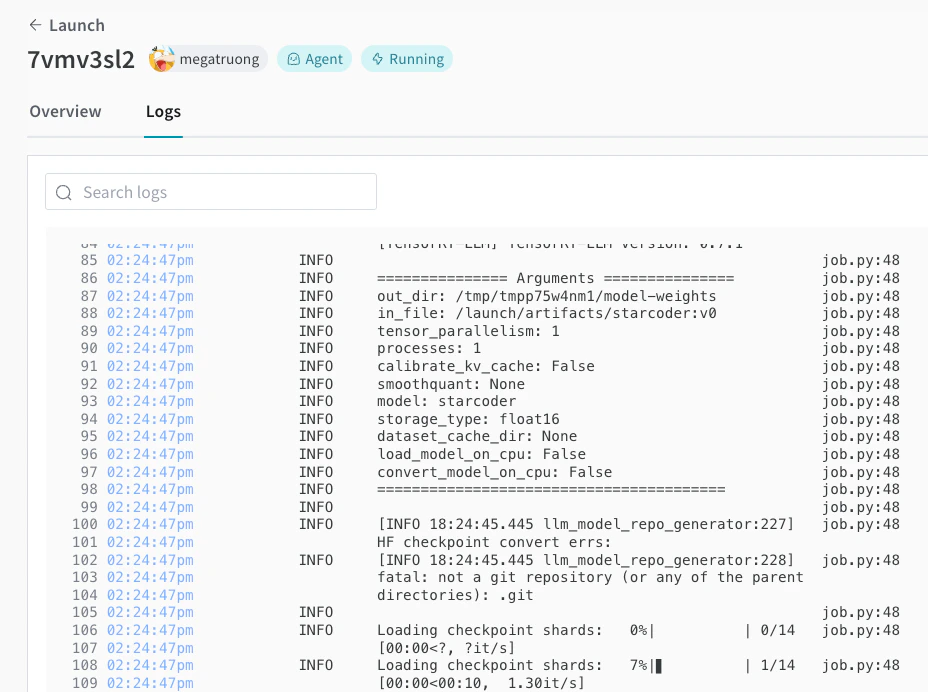
-
Une fois l’opération terminée, vous pouvez immédiatement appeler l’endpoint avec
curlpour tester le modèle. Le nom du modèle est toujoursensemble.