W&B から NVIDIA NeMo Inference Microservice にモデルアーティファクトをデプロイします。これを行うには、W&B Launch を使用します。W&B Launch はモデルアーティファクトを NVIDIA NeMo Model に変換し、実行中の NIM/Triton サーバーにデプロイします。 W&B Launch は現在、以下の互換性のあるモデルタイプをサポートしています。Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
デプロイ時間は、モデルとマシンタイプによって異なります。ベースの Llama2-7b 設定では、Google Cloud の
a2-ultragpu-1g で約 1 分かかります。クイックスタート
-
まだ作成していない場合は、Launch queue を作成します。以下にキュー設定の例を示します。
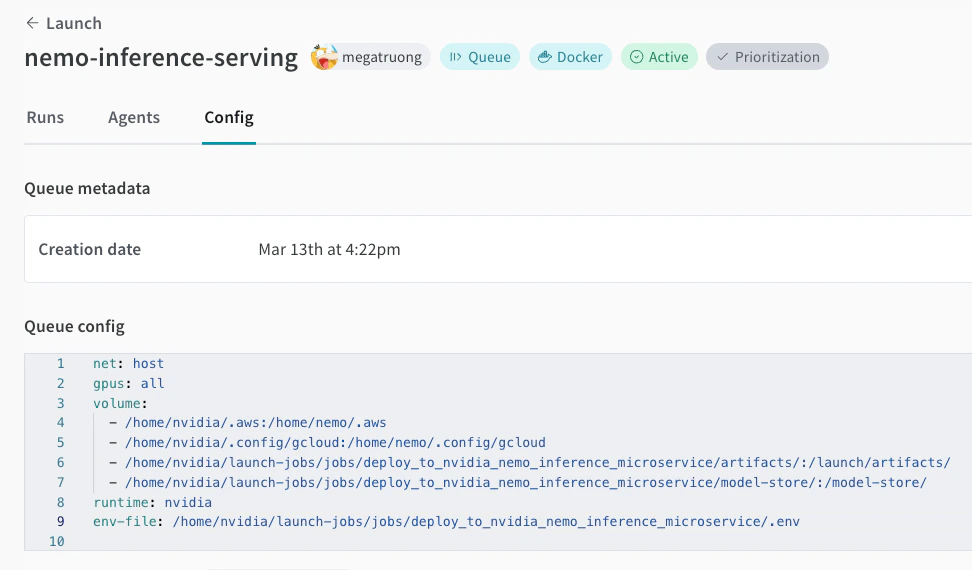
-
プロジェクト内でこのジョブを作成します。
-
GPU マシンでエージェントを起動します。
-
Launch UI から、必要な設定を指定してデプロイ用の launch ジョブを送信します。
- CLI から送信することもできます。
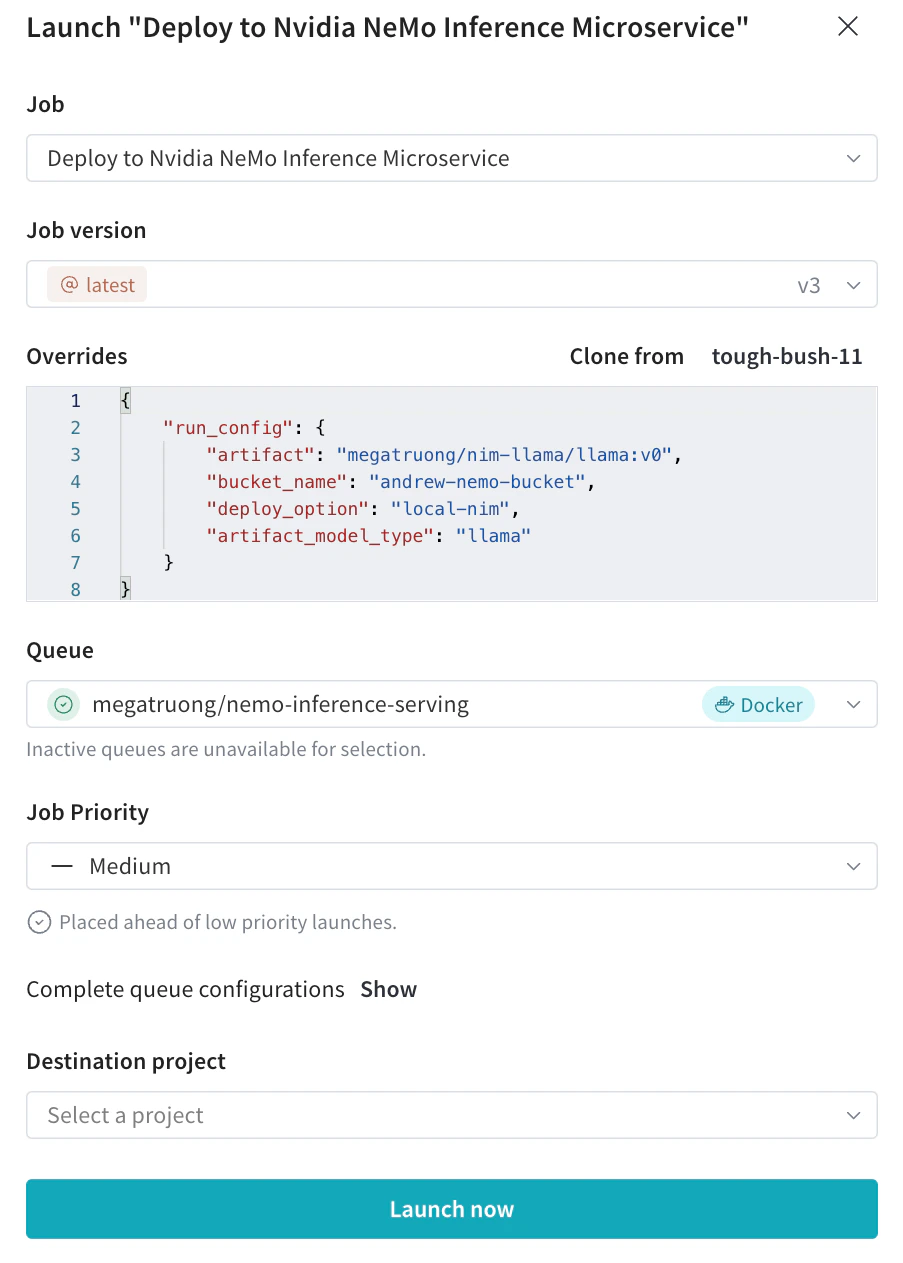
- CLI から送信することもできます。
-
Launch UI でデプロイの進行状況をトラッキングできます。
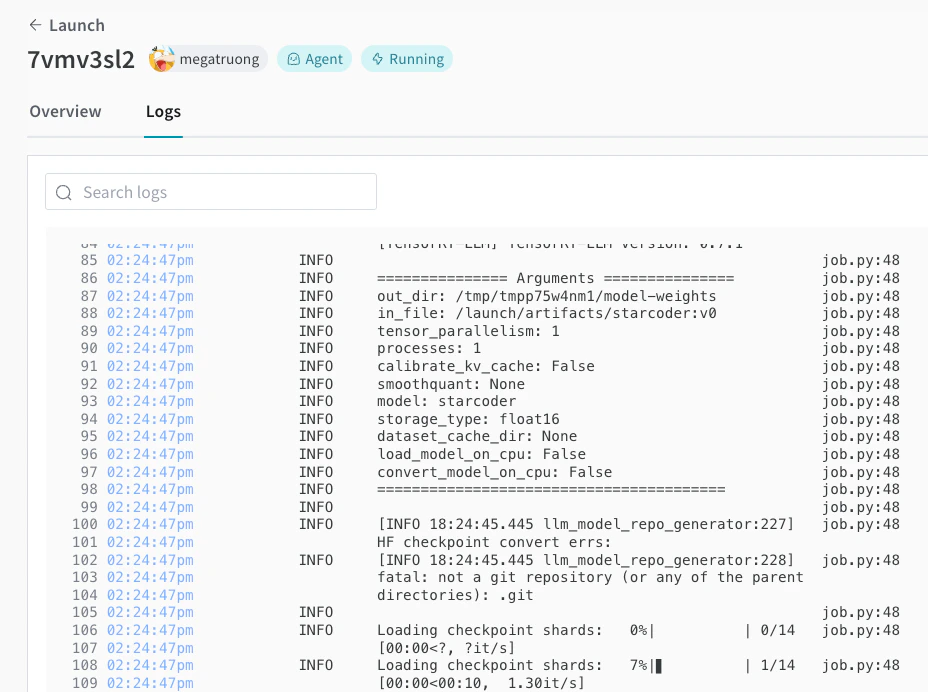
-
完了したら、すぐにエンドポイントに curl リクエストを送ってモデルをテストできます。モデル名は常に
ensembleです。