Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
W&B Weave は、LLM や GenAI アプリケーションの評価に特化したツールキットです。スコアラー、ジャッジ、詳細なトレースなど、包括的な評価機能を備えており、モデル性能の把握と改善に役立ちます。Weave は W&B Models と統合されているため、Model Registry に保存されたモデルを評価できます。
- Scorers と ジャッジ: 精度、関連性、一貫性などに対応した、組み込みおよびカスタムの評価メトリクス
- 評価用データセット: 系統的な評価のための、正解データを含む構造化されたテストセット
- モデルのバージョン管理: モデルの異なるバージョンをトラッキングして比較
- 詳細なトレース: 完全な入出力トレースでモデルの挙動をデバッグ
- コストのトラッキング: 評価全体での API コストとトークン使用量を監視
はじめに: W&B Registry のモデルを評価する
import weave
import wandb
from typing import Any
# Weaveを初期化する
weave.init("your-entity/your-project")
# W&B RegistryからロードするChatModelを定義する
class ChatModel(weave.Model):
model_name: str
def model_post_init(self, __context):
# W&B Models Registryからモデルをダウンロードする
with wandb.init(project="your-project", job_type="model_download") as run:
artifact = run.use_artifact(self.model_name)
self.model_path = artifact.download()
# ここでモデルを初期化する
@weave.op()
async def predict(self, query: str) -> str:
# モデルの推論ロジック
return self.model.generate(query)
# 評価データセットを作成する
dataset = weave.Dataset(name="eval_dataset", rows=[
{"input": "What is the capital of France?", "expected": "Paris"},
{"input": "What is 2+2?", "expected": "4"},
])
# スコアラーを定義する
@weave.op()
def exact_match_scorer(expected: str, output: str) -> dict:
return {"correct": expected.lower() == output.lower()}
# 評価を実行する
model = ChatModel(model_name="wandb-entity/registry-name/model:version")
evaluation = weave.Evaluation(
dataset=dataset,
scorers=[exact_match_scorer]
)
results = await evaluation.evaluate(model)
Weave の評価を W&B Models と統合する
- Registry からモデルを読み込む: W&B Models Registry に保存されたファインチューニング済みモデルをダウンロードする
- 評価パイプラインを作成する: カスタム スコアラー を使用して包括的な評価を構築する
- 結果を W&B にログする: 評価メトリクスをモデルの run に関連付ける
- 評価済みモデルをバージョン管理する: 改善したモデルを Registry に保存し直す
評価結果を Weave と W&B Models の両方にログします。
# W&B トラッキングで評価を実行する
with weave.attributes({"wandb-run-id": wandb.run.id}):
summary, call = await evaluation.evaluate.call(evaluation, model)
# W&B Models にメトリクスをログする
wandb.run.log(summary)
wandb.run.config.update({
"weave_eval_url": f"https://wandb.ai/{entity}/{project}/r/call/{call.id}"
})
@weave.op()
def llm_judge_scorer(expected: str, output: str, judge_model) -> dict:
prompt = f"Is this answer correct? Expected: {expected}, Got: {output}"
judgment = await judge_model.predict(prompt)
return {"judge_score": judgment}
models = [
ChatModel(model_name="model:v1"),
ChatModel(model_name="model:v2"),
]
for model in models:
results = await evaluation.evaluate(model)
print(f"{model.model_name}: {results}")
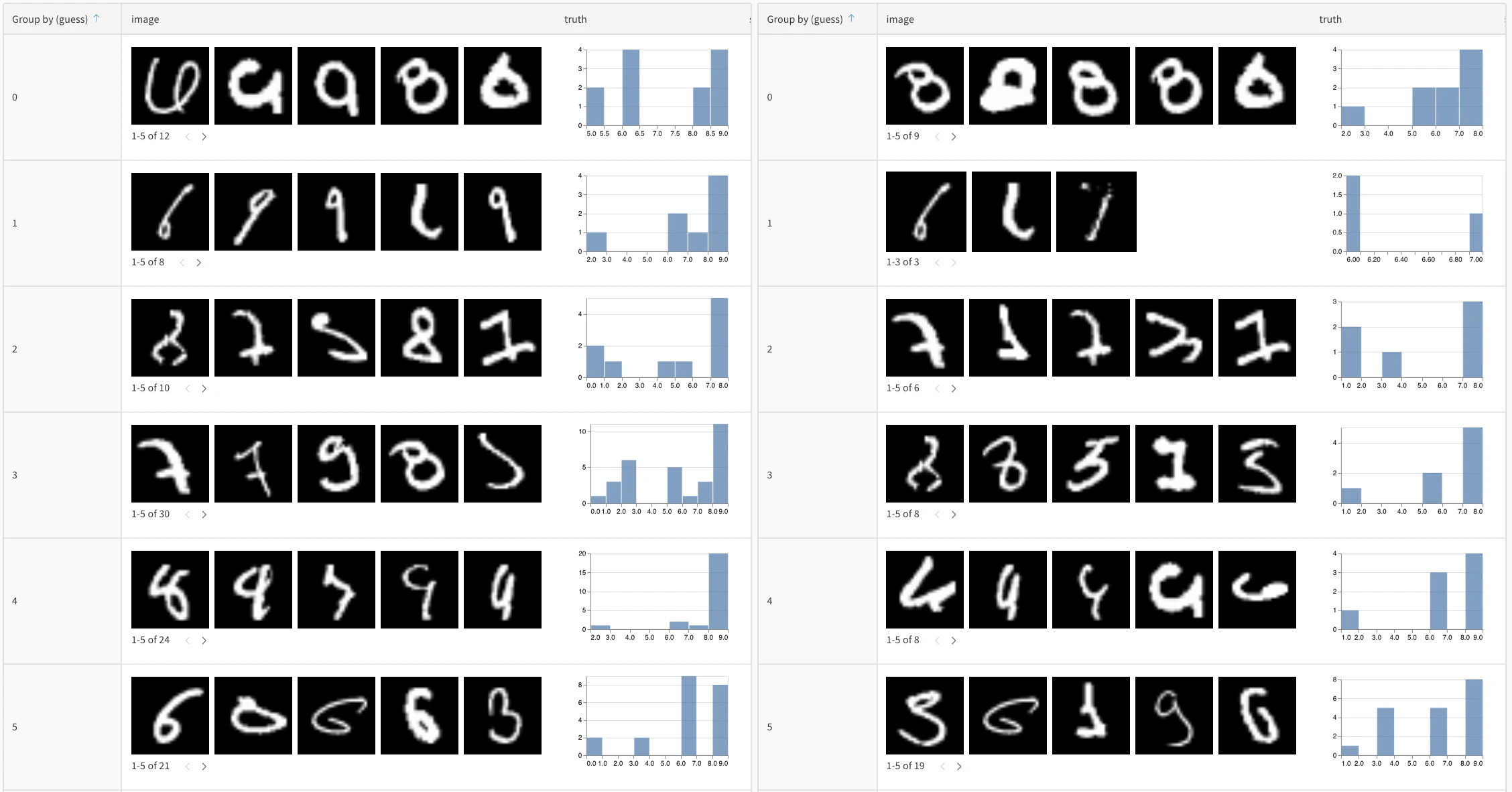
- モデルの予測を比較する: 同じテストセットに対する複数のモデルのパフォーマンスを並べて比較できます
- 予測の変化をトラッキングする: トレーニングのエポックやモデルバージョンごとに、予測がどのように変化するかを追跡できます
- エラーを分析する: フィルターやクエリを使用して、誤分類されやすい例やエラーパターンを見つけられます
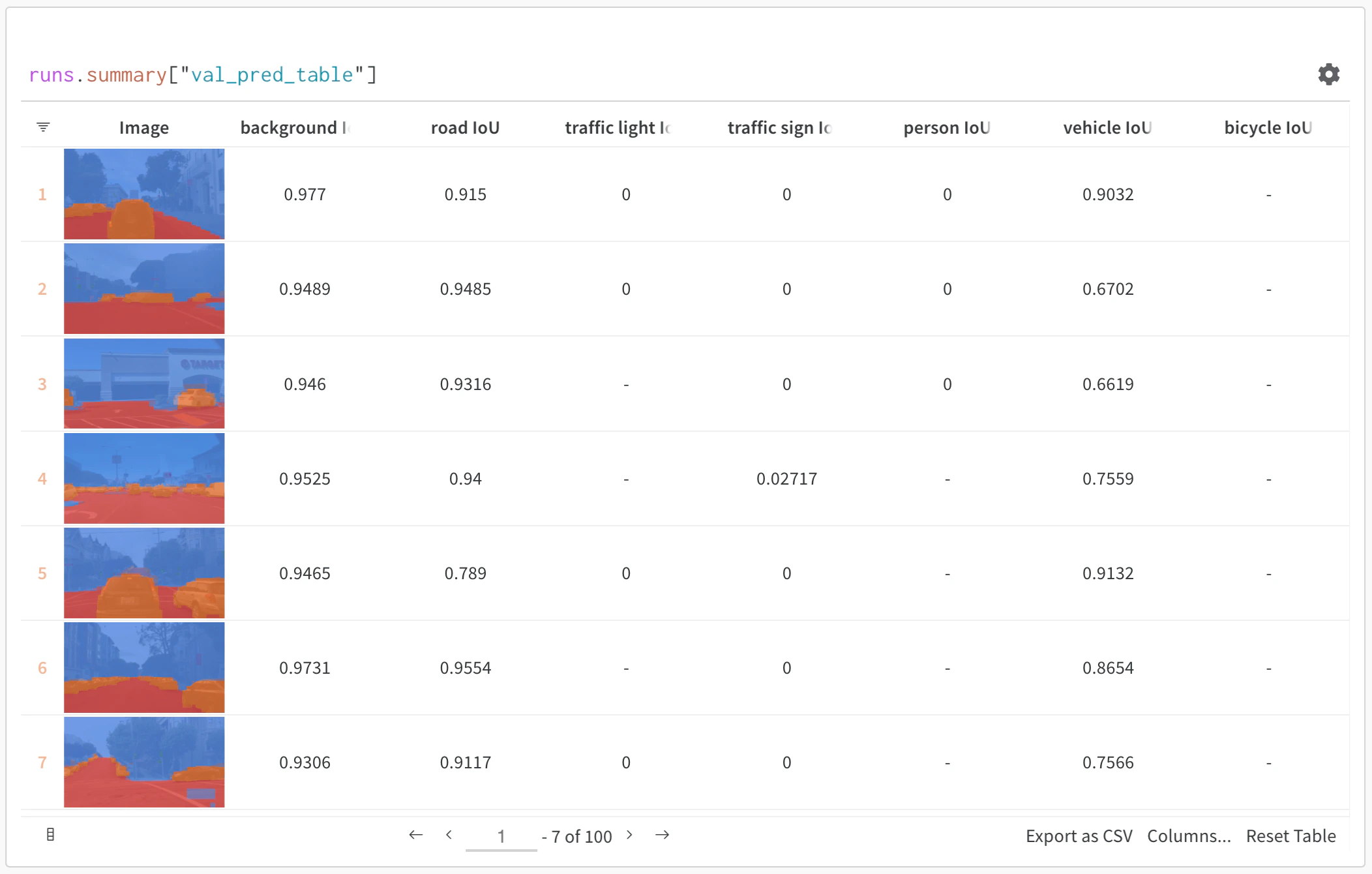
- リッチメディアを可視化する: 画像、オーディオ、テキストなどのメディアタイプを、予測やメトリクスとあわせて表示できます
import wandb
# runを初期化する
run = wandb.init(project="model-evaluation")
# 評価結果を含む表を作成する
columns = ["id", "input", "ground_truth", "prediction", "confidence", "correct"]
eval_table = wandb.Table(columns=columns)
# 評価データを追加する
for idx, (input_data, label) in enumerate(test_dataset):
prediction = model(input_data)
confidence = prediction.max()
predicted_class = prediction.argmax()
eval_table.add_data(
idx,
wandb.Image(input_data), # 画像やその他のメディアをログする
label,
predicted_class,
confidence,
label == predicted_class
)
# 表をログする
run.log({"evaluation_results": eval_table})
# モデル A の評価
with wandb.init(project="model-comparison", name="model_a") as run:
eval_table_a = create_eval_table(model_a, test_data)
run.log({"test_predictions": eval_table_a})
# モデル B の評価
with wandb.init(project="model-comparison", name="model_b") as run:
eval_table_b = create_eval_table(model_b, test_data)
run.log({"test_predictions": eval_table_b})
for epoch in range(num_epochs):
train_model(model, train_data)
# このエポックの予測を評価してログする
eval_table = wandb.Table(columns=["image", "truth", "prediction"])
for image, label in test_subset:
pred = model(image)
eval_table.add_data(wandb.Image(image), label, pred.argmax())
wandb.log({f"predictions_epoch_{epoch}": eval_table})
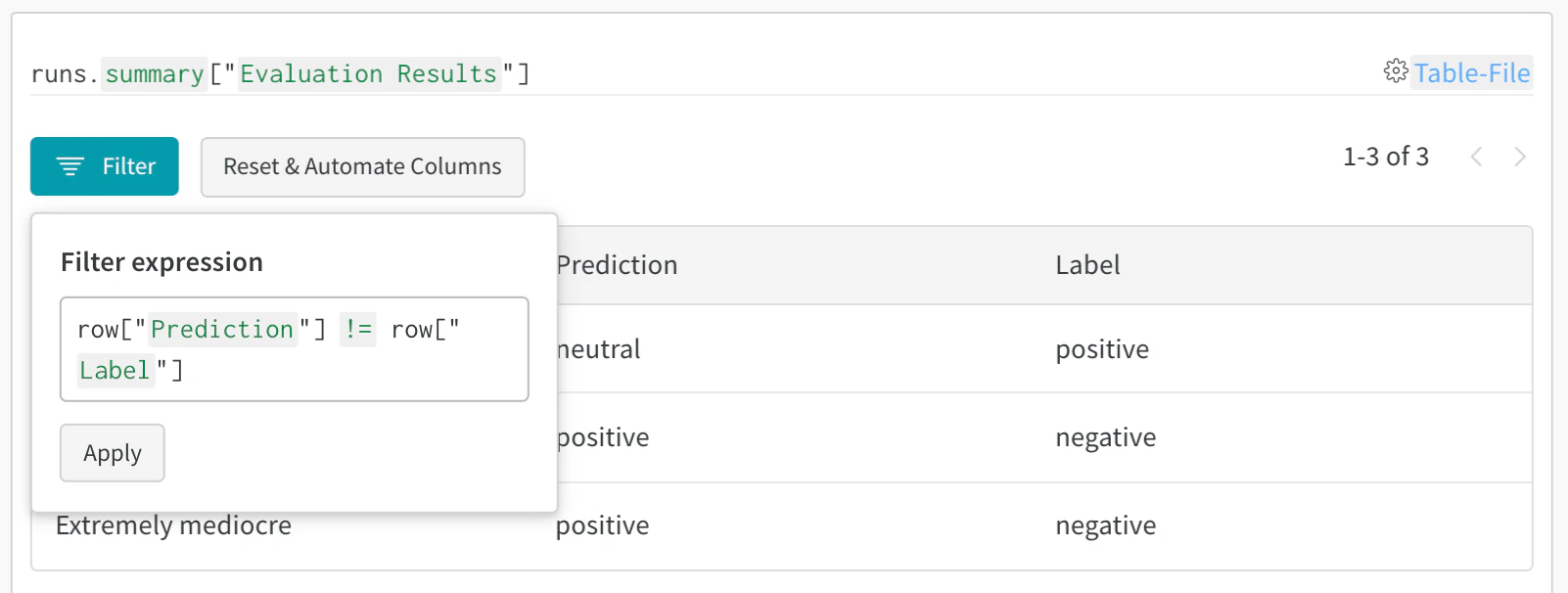
- 結果をフィルター: 列ヘッダーをクリックして、予測精度、信頼度のしきい値、特定のクラスで絞り込みます
- テーブルを比較: 複数のテーブルバージョンを選択して、並べて比較できます
- データをクエリ: クエリバーを使用して特定のパターンを検索します (例:
"correct" = false AND "confidence" > 0.8)
- グループ化と集計: 予測クラスでグループ化して、クラスごとの精度メトリクスを確認します
# 分析列を追加するための可変テーブルを作成する
eval_table = wandb.Table(
columns=["id", "image", "label", "prediction"],
log_mode="MUTABLE" # 後から列を追加できる
)
# 初期予測
for idx, (img, label) in enumerate(test_data):
pred = model(img)
eval_table.add_data(idx, wandb.Image(img), label, pred.argmax())
run.log({"eval_analysis": eval_table})
# エラー分析用の信頼度スコアを追加する
confidences = [model(img).max() for img, _ in test_data]
eval_table.add_column("confidence", confidences)
# エラータイプを追加する
error_types = classify_errors(eval_table.get_column("label"),
eval_table.get_column("prediction"))
eval_table.add_column("error_type", error_types)
run.log({"eval_analysis": eval_table})