Deploy a model artifact from W&B to a NVIDIA NeMo Inference Microservice. To do this, use W&B Launch. W&B Launch converts model artifacts to NVIDIA NeMo Model and deploys to a running NIM/Triton server. W&B Launch currently accepts the following compatible model types:Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Deployment time varies by model and machine type. The base Llama2-7b config takes about 1 minute on Google Cloud’s
a2-ultragpu-1g.Quickstart
-
Create a launch queue if you don’t have one already. See an example queue config below.
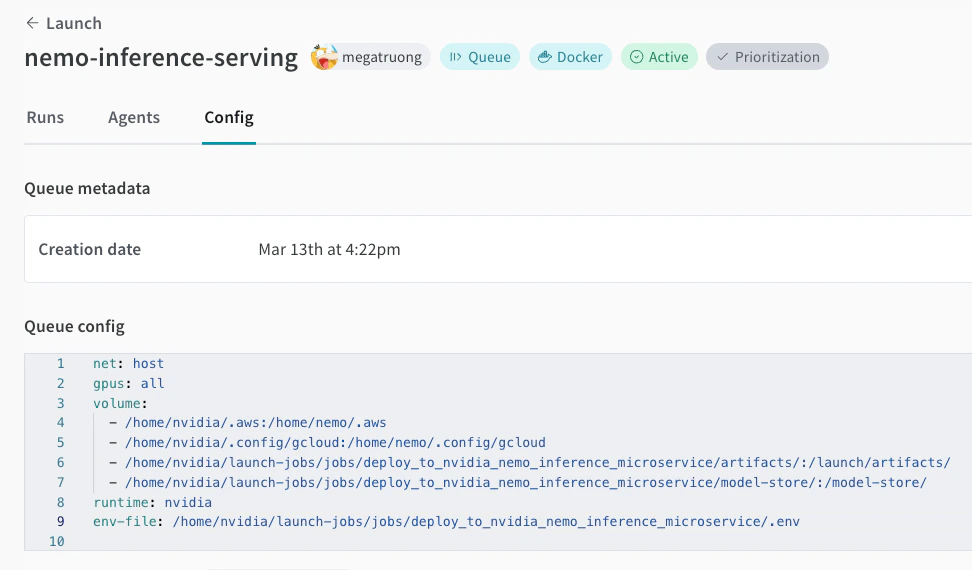
-
Create this job in your project:
-
Launch an agent on your GPU machine:
-
Submit the deployment launch job with your desired configs from the Launch UI
- You can also submit via the CLI:
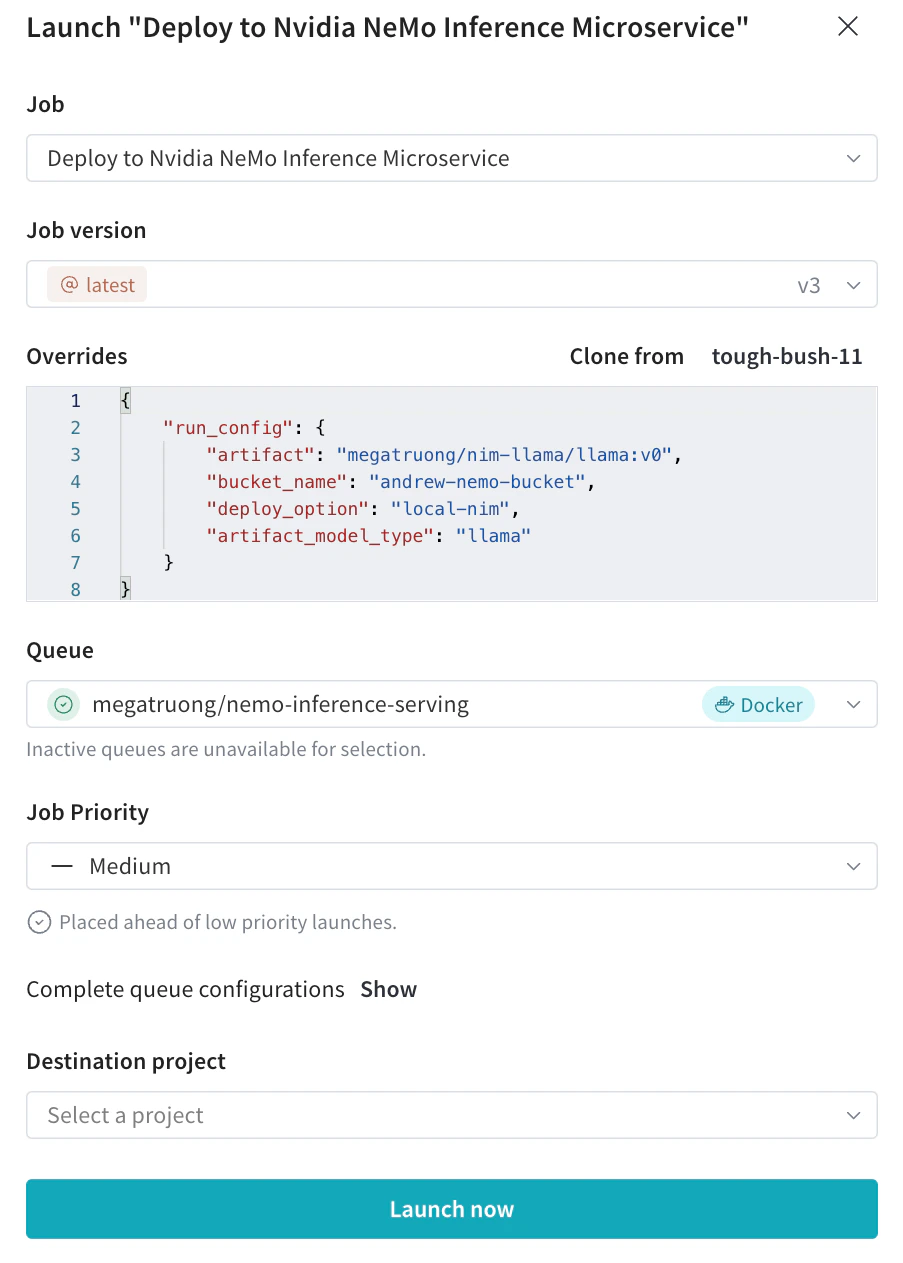
- You can also submit via the CLI:
-
You can track the deployment process in the Launch UI.
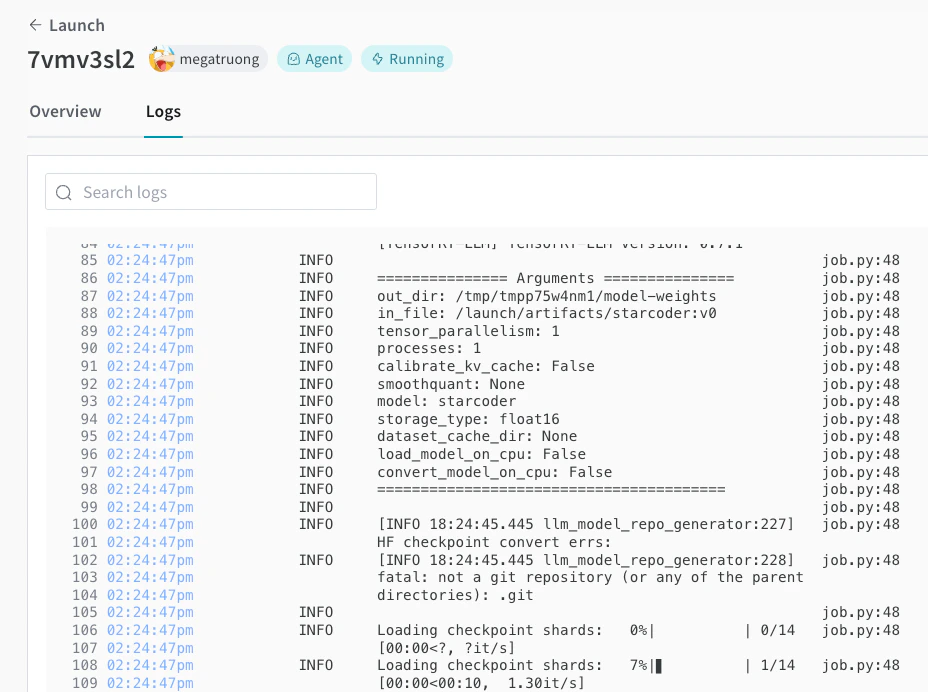
-
Once complete, you can immediately curl the endpoint to test the model. The model name is always
ensemble.