Use this file to discover all available pages before exploring further.
Utilisez les Leaderboards de Weave pour évaluer et comparer plusieurs modèles selon plusieurs métriques, et mesurer la précision, la qualité de génération, la latence ou une logique d’évaluation personnalisée. Un leaderboard vous aide à visualiser les performances du modèle dans un emplacement centralisé, à suivre les changements au fil du temps et à vous aligner sur des benchmarks communs pour toute l’équipe.Les leaderboards sont idéaux pour :
Suivre les régressions des performances du modèle
Coordonner des flux de travail d’évaluation partagés
La création de leaderboards n’est possible que dans la Weave UI et le SDK Python de Weave. Les utilisateurs de TypeScript peuvent créer et gérer des leaderboards à l’aide de la Weave UI.
L’exemple suivant utilise les évaluations Weave et crée un leaderboard pour comparer trois modèles de résumé sur un jeu de données partagé à l’aide d’une métrique personnalisée. Il crée un petit benchmark, évalue chaque modèle, calcule le score de chaque modèle à l’aide de la similarité de Jaccard, puis publie les résultats dans un leaderboard Weave.
import weavefrom weave.flow import leaderboardfrom weave.trace.ref_util import get_refimport asyncioclient = weave.init("leaderboard-demo")dataset = [ { "input": "Weave is a tool for building interactive LLM apps. It offers observability, trace inspection, and versioning.", "target": "Weave helps developers build and observe LLM applications." }, { "input": "The OpenAI GPT-4o model can process text, audio, and vision inputs, making it a multimodal powerhouse.", "target": "GPT-4o is a multimodal model for text, audio, and images." }, { "input": "The W&B team recently added native support for agents and evaluations in Weave.", "target": "W&B added agents and evals to Weave." }]@weave.opdef jaccard_similarity(target: str, output: str) -> float: target_tokens = set(target.lower().split()) output_tokens = set(output.lower().split()) intersection = len(target_tokens & output_tokens) union = len(target_tokens | output_tokens) return intersection / union if union else 0.0evaluation = weave.Evaluation( name="Summarization Quality", dataset=dataset, scorers=[jaccard_similarity],)@weave.opdef model_vanilla(input: str) -> str: return input[:50]@weave.opdef model_humanlike(input: str) -> str: if "Weave" in input: return "Weave helps developers build and observe LLM applications." elif "GPT-4o" in input: return "GPT-4o supports text, audio, and vision input." else: return "W&B added agent support to Weave."@weave.opdef model_messy(input: str) -> str: return "Summarizer summarize models model input text LLMs."async def run_all(): await evaluation.evaluate(model_vanilla) await evaluation.evaluate(model_humanlike) await evaluation.evaluate(model_messy)asyncio.run(run_all())spec = leaderboard.Leaderboard( name="Summarization Model Comparison", description="Evaluate summarizer models using Jaccard similarity on 3 short samples.", columns=[ leaderboard.LeaderboardColumn( evaluation_object_ref=get_ref(evaluation).uri(), scorer_name="jaccard_similarity", summary_metric_path="mean", ) ])weave.publish(spec)results = leaderboard.get_leaderboard_results(spec, client)print(results)
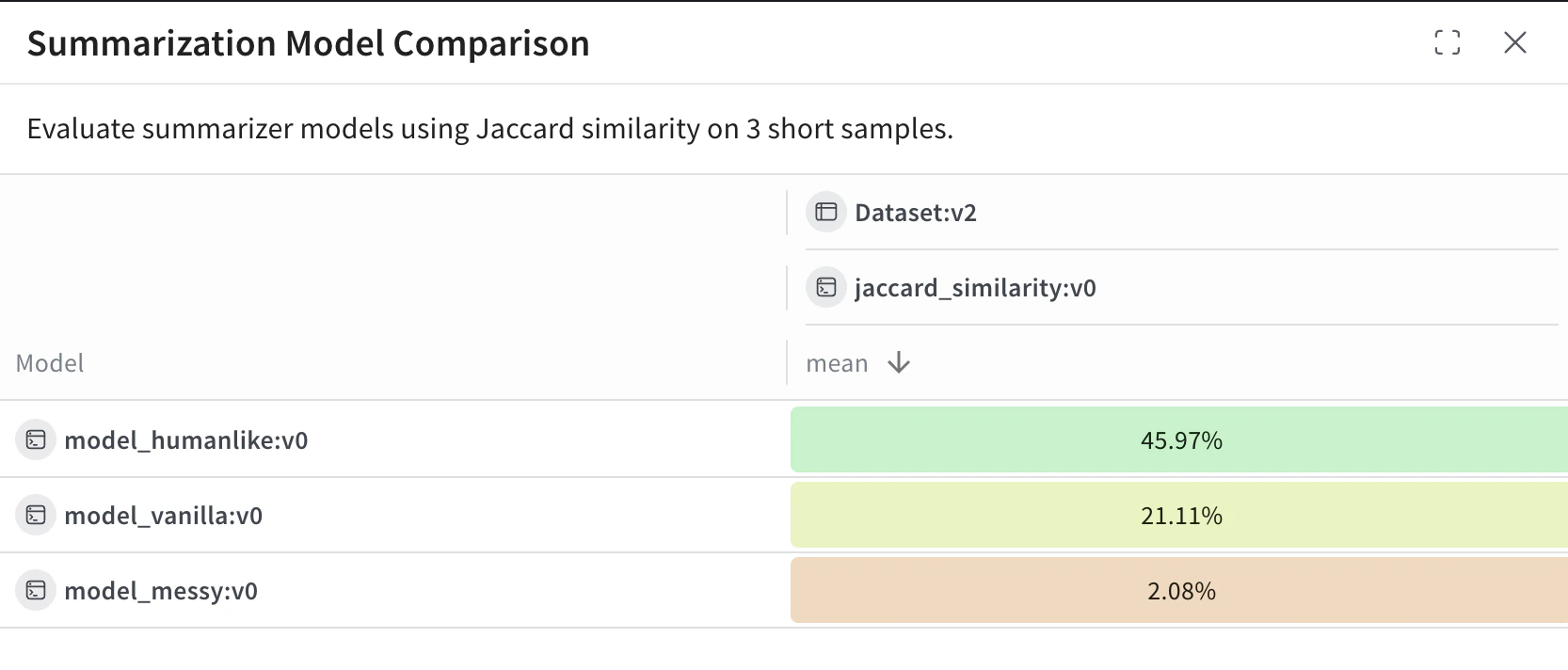
Une fois le script exécuté, affichez le leaderboard :
Dans la Weave UI, accédez à l’onglet Leaders. S’il n’est pas visible, cliquez sur More, puis sélectionnez Leaders.
Cliquez sur le nom de votre leaderboard, par exemple Summarization Model Comparison.
Dans le tableau du leaderboard, chaque ligne représente un modèle (model_humanlike, model_vanilla, model_messy). La colonne mean indique la similarité de Jaccard moyenne entre la sortie du modèle et les résumés de référence.
Pour cet exemple :
model_humanlike donne les meilleurs résultats, avec ~46 % de chevauchement.