Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Weave assure automatiquement le suivi et la tenue d’un journal des appels LLM effectués via le SDK Cerebras Cloud.
Le suivi des appels LLM est crucial pour le débogage et la surveillance des performances. Weave vous aide à le faire en capturant automatiquement des traces pour le SDK Cerebras Cloud.
Voici un exemple montrant comment utiliser Weave avec Cerebras :
import os
import weave
from cerebras.cloud.sdk import Cerebras
# Initialiser le projet weave
weave.init("cerebras_speedster")
# Utiliser le SDK Cerebras comme d'habitude
api_key = os.environ["CEREBRAS_API_KEY"]
model = "llama3.1-8b" # modèle Cerebras
client = Cerebras(api_key=api_key)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "What's the fastest land animal?"}],
)
print(response.choices[0].message.content)

Encapsuler dans vos propres ops
import os
import weave
from cerebras.cloud.sdk import Cerebras
# Initialiser le projet weave
weave.init("cerebras_speedster")
client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"])
# Weave suivra les entrées, sorties et le code de cette fonction
@weave.op
def animal_speedster(animal: str, model: str) -> str:
"Découvrir à quelle vitesse un animal peut courir"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": f"How fast can a {animal} run?"}],
)
return response.choices[0].message.content
animal_speedster("cheetah", "llama3.1-8b")
animal_speedster("ostrich", "llama3.1-8b")
animal_speedster("human", "llama3.1-8b")
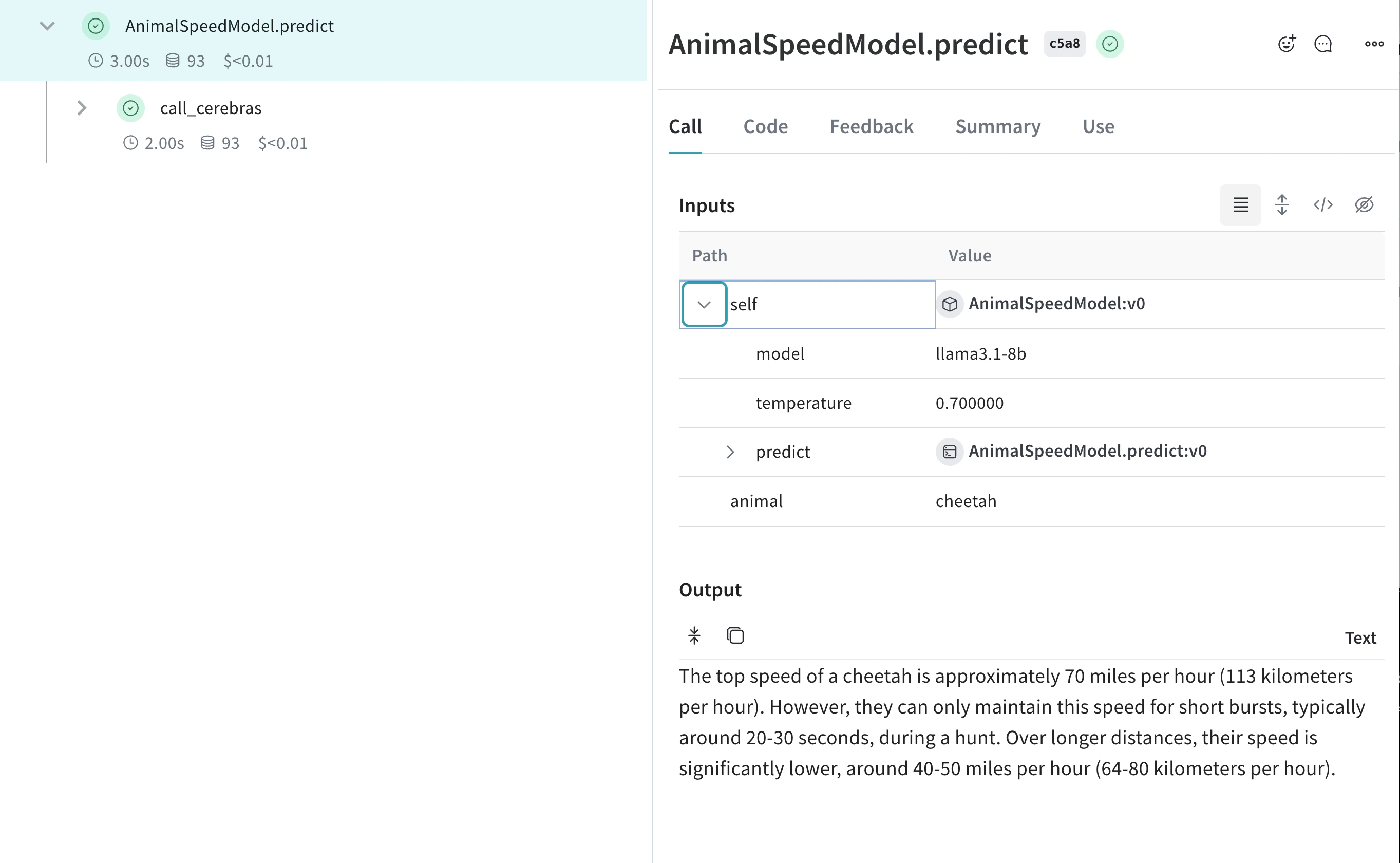
Créer un Model pour expérimenter plus facilement
import os
import weave
from cerebras.cloud.sdk import Cerebras
# Initialiser le projet weave
weave.init("cerebras_speedster")
client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"])
class AnimalSpeedModel(weave.Model):
model: str
temperature: float
@weave.op
def predict(self, animal: str) -> str:
"Prédire la vitesse maximale d'un animal"
response = client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": f"What's the top speed of a {animal}?"}],
temperature=self.temperature
)
return response.choices[0].message.content
speed_model = AnimalSpeedModel(
model="llama3.1-8b",
temperature=0.7
)
result = speed_model.predict(animal="cheetah")
print(result)