LLM Evaluation Jobs は、CoreWeave が管理するインフラストラクチャーを利用して LLM モデルのパフォーマンスを評価するためのベンチマーク フレームワークです。最新の業界標準に準拠した包括的なモデル評価ベンチマークから選択し、W&B Models の自動リーダーボードやチャートを使って結果の確認、分析、共有を行えます。LLM Evaluation Jobs を使えば、GPU インフラストラクチャーを自分でデプロイして維持管理する複雑さを解消できます。Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
LLM 評価ジョブは、W&B Multi-tenant Cloud でプレビュー版として提供されています。プレビュー期間中は、コンピュートを無料で利用できます。詳細はこちら
仕組み
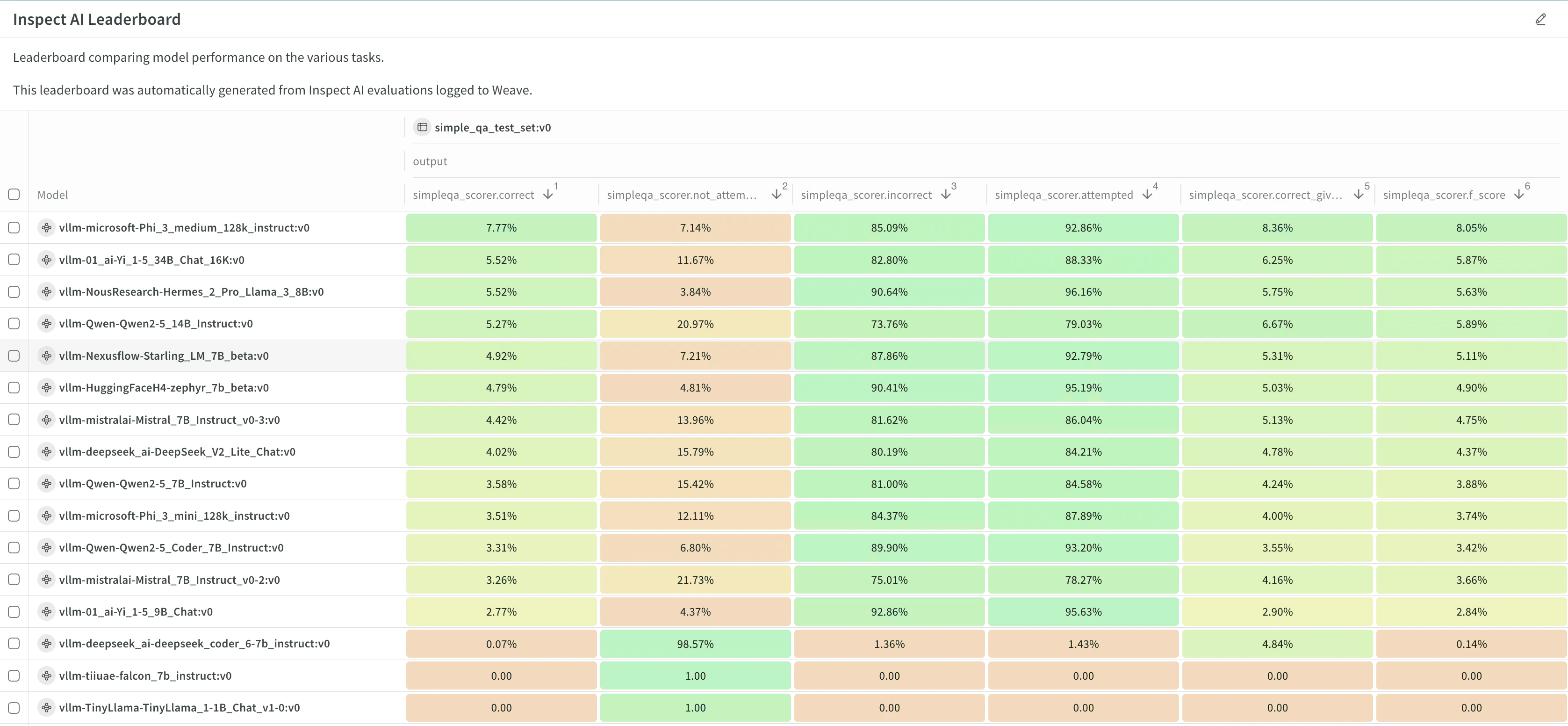
- W&B Models で評価ジョブを設定します。ベンチマークや設定 (リーダーボードを生成するかどうかなど) を定義します。
- 評価ジョブを Launch します。
- 結果とリーダーボードを確認し、分析します。
次のステップ
詳細情報
Pricing
ジョブの制限
- 評価対象のモデルの最大サイズは、コンテキストを含めて 86 GB です。
- 各ジョブで使用できる GPU は 2 基までです。
要件
- モデル チェックポイントを評価するには、モデルの重みを VLLM 互換のartifactとしてパッケージ化する必要があります。詳細とコード例については、例: モデルを準備するを参照してください。
- OpenAI 互換モデルを評価するには、そのモデルに公開 URL でアクセスできる必要があります。また、認証用のAPIキーを含むチームシークレットを、組織またはチーム管理者が設定する必要があります。
- 一部のベンチマークでは、スコアリングに OpenAI モデルを使用します。これらのベンチマークを実行するには、組織またはチーム管理者が必要なAPIキーを含むチームシークレットを設定する必要があります。ベンチマークにこの要件があるかどうかを確認するには、評価ベンチマークカタログを参照してください。
- 一部のベンチマークでは、Hugging Face のgated datasetへのアクセスが必要です。これらのベンチマークのいずれかを実行するには、組織またはチーム管理者が Hugging Face でgated datasetへのアクセスをリクエストし、Hugging Face のユーザーアクセストークンを生成して、チームシークレットとして設定する必要があります。ベンチマークにこの要件があるかどうかを確認するには、評価ベンチマークカタログを参照してください。