Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Verifiers は、強化学習 (RL) 環境の作成や LLM エージェントのトレーニングに使う、モジュール型コンポーネントのライブラリです。Verifiers で構築した環境は、LLM の評価、合成データパイプライン、任意の OpenAI 互換 endpoint 向けのエージェントハーネス、RL トレーニングに利用できます。
W&B を使用してトレーニングメトリクスを記録するだけでなく、Verifiers の RL ワークフローに Weave を統合することで、トレーニング中のモデルの挙動を可視化できます。Weave は各 step の inputs、outputs、タイムスタンプを記録するため、各ターンでデータがどのように変換されるかを確認し、複雑な複数ラウンドの会話をデバッグし、トレーニング結果を最適化できます。
また、Weave と Verifiers を組み合わせて使用して、評価を実行することもできます。
このガイドでは、Verifiers、W&B、Weave のインストール方法を説明し、Verifiers を Weave および W&B と組み合わせて使う 2 つの例を紹介します。
 Verifiers を Weave と統合するには、まず
Verifiers を Weave と統合するには、まず uv を使って Verifiers ライブラリをインストールします (ライブラリの作者が推奨しています) 。ライブラリのインストールには、次のいずれかのコマンドを使用してください。
# ローカル開発および API ベースのモデル向けにコアライブラリをインストールします
uv add verifiers
# PyTorch および GPU サポートを含む、すべてのオプション依存関係を含むライブラリの完全版をインストールします
uv add 'verifiers[all]' && uv pip install flash-attn --no-build-isolation
# 未リリースの最新機能や修正を含む、ライブラリの最新版を GitHub から直接インストールします
uv add verifiers @ git+https://github.com/willccbb/verifiers.git
uv pip install weave wandb
import os
from openai import OpenAI
import verifiers as vf
import weave
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
# Weave を初期化する
weave.init("verifiers_demo")
# 最小限のシングルターン環境
dataset = vf.load_example_dataset("gsm8k", split="train").select(range(2))
parser = vf.ThinkParser()
def correct_answer(parser, completion, answer):
parsed = parser.parse_answer(completion) or ""
return 1.0 if parsed.strip() == answer.strip() else 0.0
rubric = vf.Rubric(funcs=[correct_answer, parser.get_format_reward_func()], weights=[1.0, 0.2])
env = vf.SingleTurnEnv(
dataset=dataset,
system_prompt="Think step-by-step, then answer.",
parser=parser,
rubric=rubric,
)
client = OpenAI()
results = env.evaluate(
client, "gpt-4.1-mini", num_examples=2, rollouts_per_example=2, max_concurrent=8
)
実験管理とトレースを使用してモデルをファインチューニングする
verifiers repository には、使い始めるのに役立つ、すぐに実行できる例が含まれています。
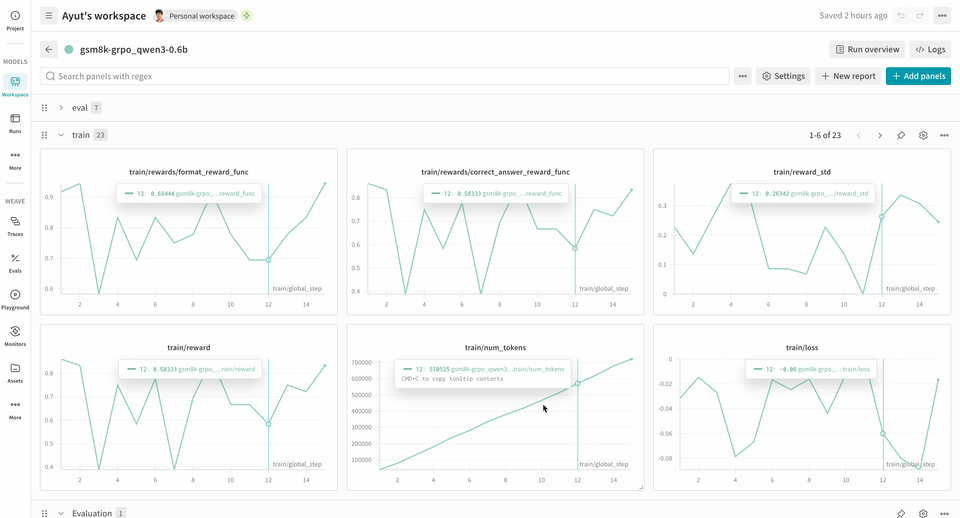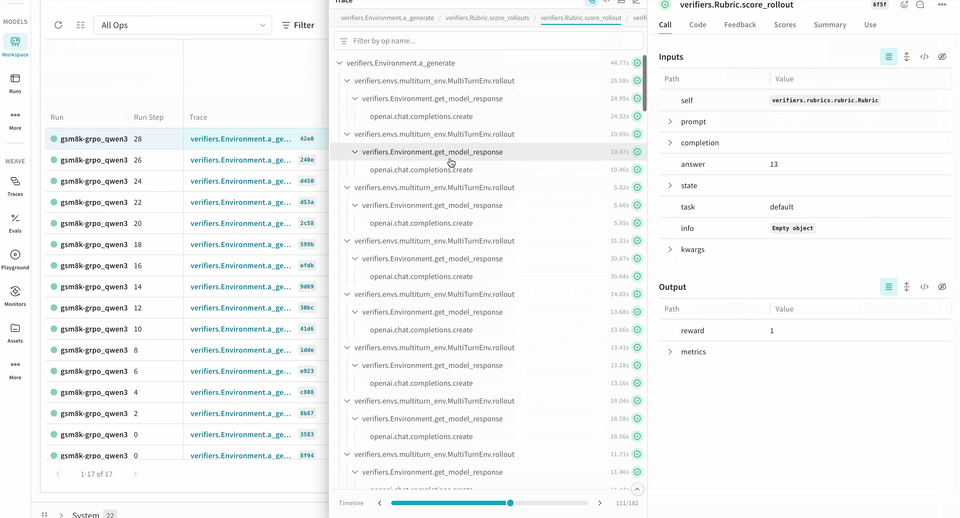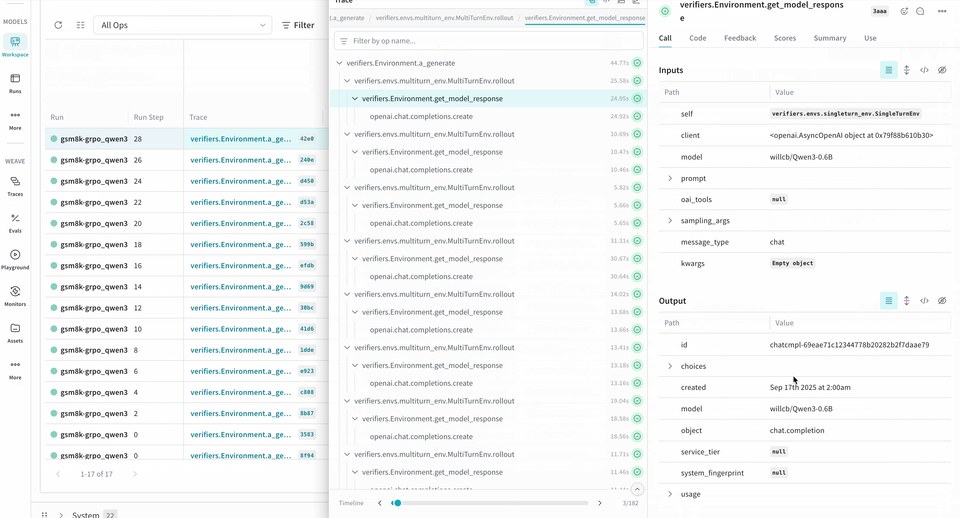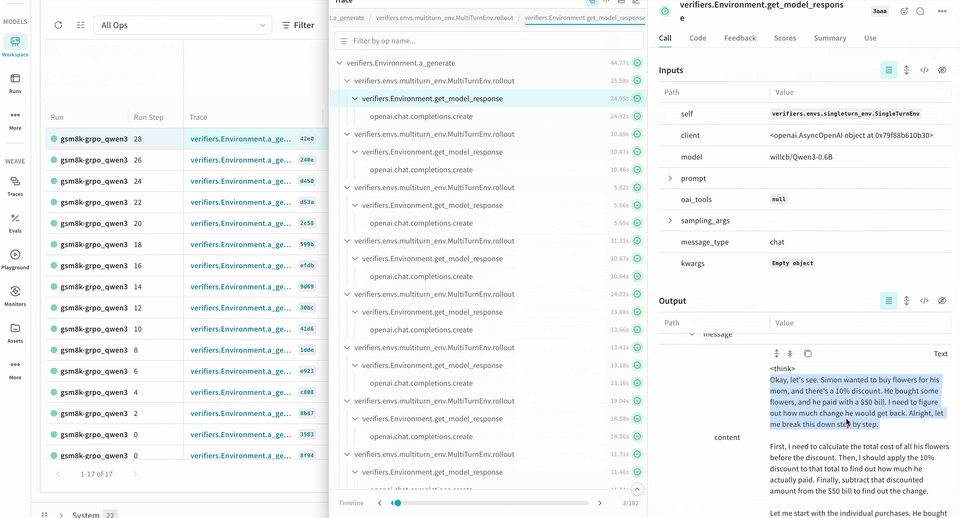
次の RL トレーニングパイプラインの例では、ローカルの推論サーバーを実行し、GSM8K データセットを使用してモデルをトレーニングします。モデルは数学の問題に対する答えを返し、トレーニングループは出力をスコアリングして、それに応じてモデルを更新します。W&B は損失、報酬、精度などのトレーニングメトリクスをログし、Weave は入力、出力、推論過程、スコアリングを取得します。
このパイプラインを使用するには:
- ソースからフレームワークをインストールします。次のコマンドでは、GitHub から Verifiers ライブラリと必要な依存関係をインストールします。
git clone https://github.com/willccbb/verifiers
cd verifiers
uv sync --all-extras && uv pip install flash-attn --no-build-isolation
- 既成の環境をインストールします。次のコマンドで、事前設定済みの GSM8K トレーニング環境をインストールできます。
vf-install gsm8k --from-repo
- モデルをトレーニングします。次のコマンドは、それぞれ推論サーバーとトレーニングループを起動します。このワークフロー例では、デフォルトで
report_to=wandb が設定されているため、wandb.init() を別途呼び出す必要はありません。W&B にメトリクスをログするには、このマシンを認証するよう求められます。
# 推論サーバーを起動する
CUDA_VISIBLE_DEVICES=0 vf-vllm --model willcb/Qwen3-0.6B --enforce-eager --disable-log-requests
# トレーニングループを起動する
CUDA_VISIBLE_DEVICES=1 accelerate launch --num-processes 1 --config-file configs/zero3.yaml examples/grpo/train_gsm8k.py
この例は 2xH100 での動作を確認しており、安定性を高めるために以下の環境変数を設定しました。# 起動前に両方のシェル(server と trainer)で設定
export NCCL_CUMEM_ENABLE=0
export NCCL_CUMEM_HOST_ENABLE=0
Environment.a_generate および Rubric.score_rollouts method の logprobs は省略されます。これにより、トレーニング用の元のデータはそのまま保持しつつ、ペイロードを小さくできます。
Verifiers は W&B Models とネイティブにインテグレーションされています。詳しくは、Verifiers repositoryを参照してください。