Use this file to discover all available pages before exploring further.
Weave _Leaderboards_를 사용하면 여러 메트릭에 걸쳐 여러 모델을 평가하고 비교하여 정확도, 생성 품질, 지연 시간 또는 맞춤형 평가 로직을 측정할 수 있습니다. 리더보드를 사용하면 한곳에서 모델 성능을 시각화하고, 시간에 따른 변화를 추적하며, 팀 전체 벤치마크에 대한 합의를 이끌어낼 수 있습니다.리더보드는 다음과 같은 경우에 적합합니다.
모델 성능 저하 추적
공유 평가 워크플로 조율
리더보드 생성은 Weave UI와 Weave Python SDK에서만 지원됩니다. TypeScript 사용자는 Weave UI를 사용해 리더보드를 생성하고 관리할 수 있습니다.
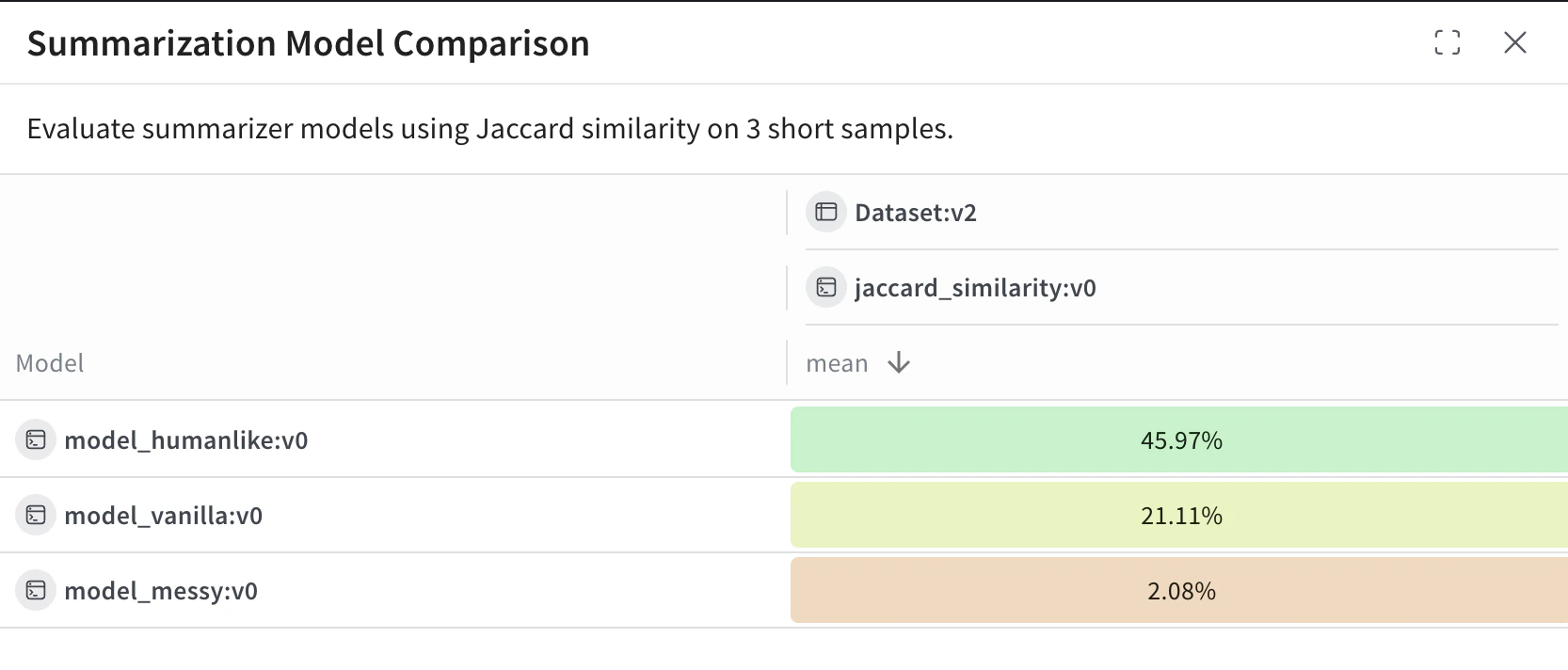
다음 예제에서는 Weave Evaluations를 사용해 맞춤형 메트릭으로 공유 데이터셋에서 세 가지 요약 모델을 비교하는 리더보드를 만듭니다. 작은 벤치마크를 만든 뒤 각 모델을 평가하고, Jaccard similarity로 각 모델의 점수를 매긴 다음, 결과를 Weave 리더보드에 게시합니다.
import weavefrom weave.flow import leaderboardfrom weave.trace.ref_util import get_refimport asyncioclient = weave.init("leaderboard-demo")dataset = [ { "input": "Weave is a tool for building interactive LLM apps. It offers observability, trace inspection, and versioning.", "target": "Weave helps developers build and observe LLM applications." }, { "input": "The OpenAI GPT-4o model can process text, audio, and vision inputs, making it a multimodal powerhouse.", "target": "GPT-4o is a multimodal model for text, audio, and images." }, { "input": "The W&B team recently added native support for agents and evaluations in Weave.", "target": "W&B added agents and evals to Weave." }]@weave.opdef jaccard_similarity(target: str, output: str) -> float: target_tokens = set(target.lower().split()) output_tokens = set(output.lower().split()) intersection = len(target_tokens & output_tokens) union = len(target_tokens | output_tokens) return intersection / union if union else 0.0evaluation = weave.Evaluation( name="Summarization Quality", dataset=dataset, scorers=[jaccard_similarity],)@weave.opdef model_vanilla(input: str) -> str: return input[:50]@weave.opdef model_humanlike(input: str) -> str: if "Weave" in input: return "Weave helps developers build and observe LLM applications." elif "GPT-4o" in input: return "GPT-4o supports text, audio, and vision input." else: return "W&B added agent support to Weave."@weave.opdef model_messy(input: str) -> str: return "Summarizer summarize models model input text LLMs."async def run_all(): await evaluation.evaluate(model_vanilla) await evaluation.evaluate(model_humanlike) await evaluation.evaluate(model_messy)asyncio.run(run_all())spec = leaderboard.Leaderboard( name="Summarization Model Comparison", description="Evaluate summarizer models using Jaccard similarity on 3 short samples.", columns=[ leaderboard.LeaderboardColumn( evaluation_object_ref=get_ref(evaluation).uri(), scorer_name="jaccard_similarity", summary_metric_path="mean", ) ])weave.publish(spec)results = leaderboard.get_leaderboard_results(spec, client)print(results)