Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
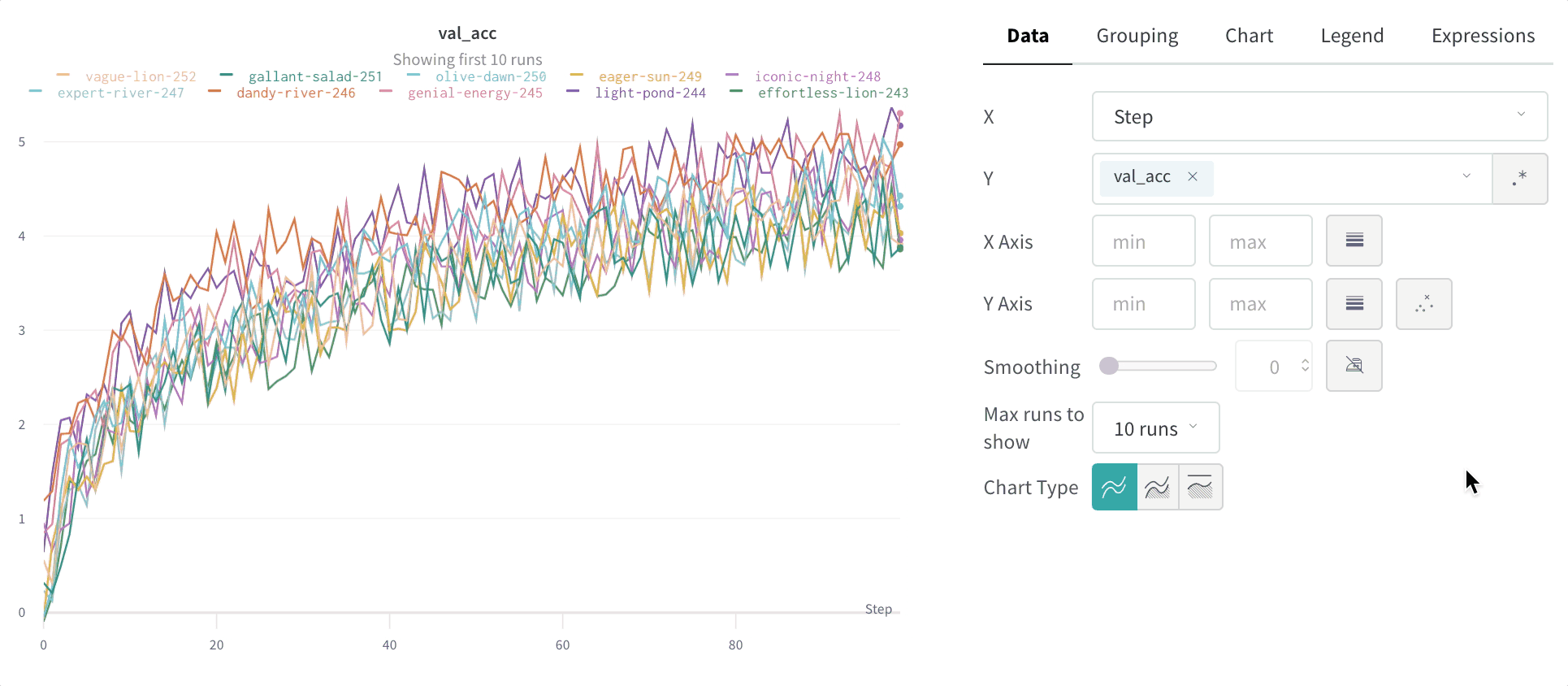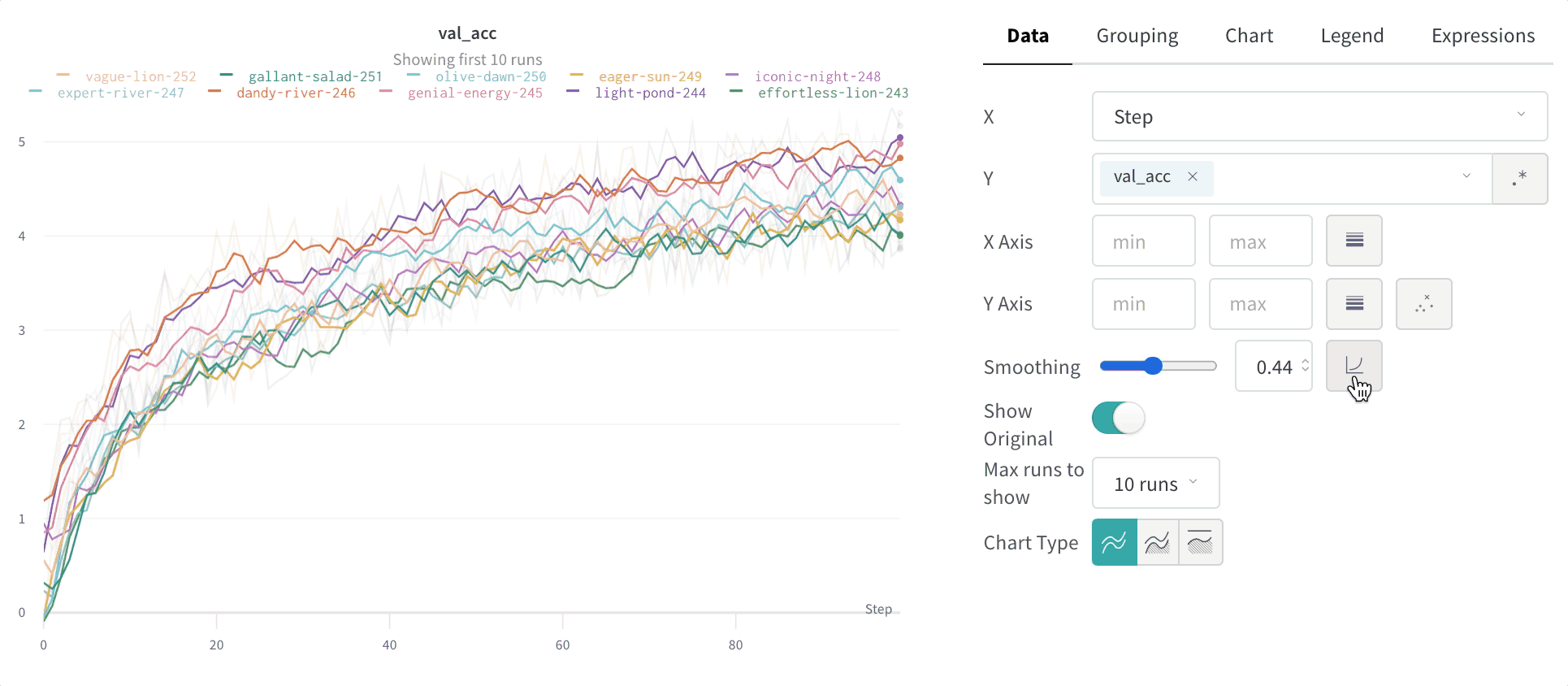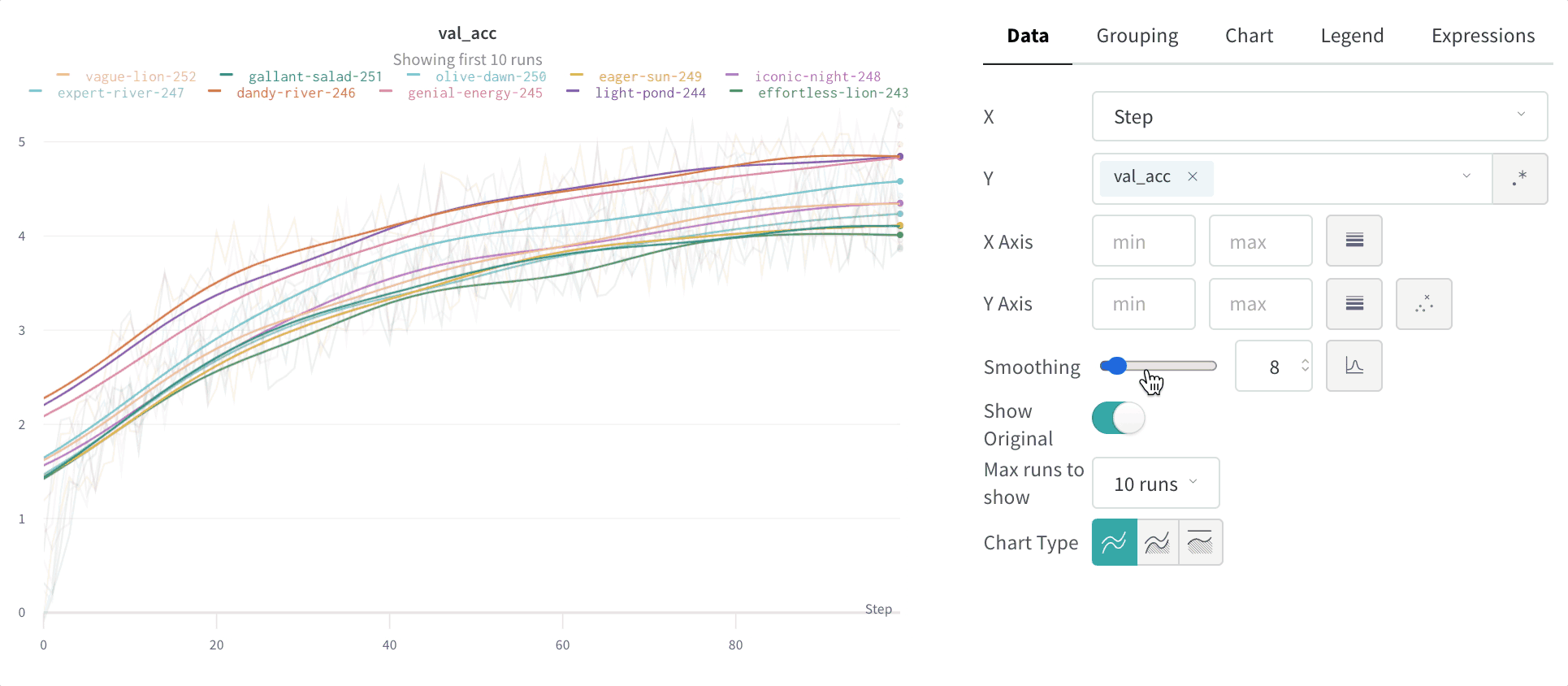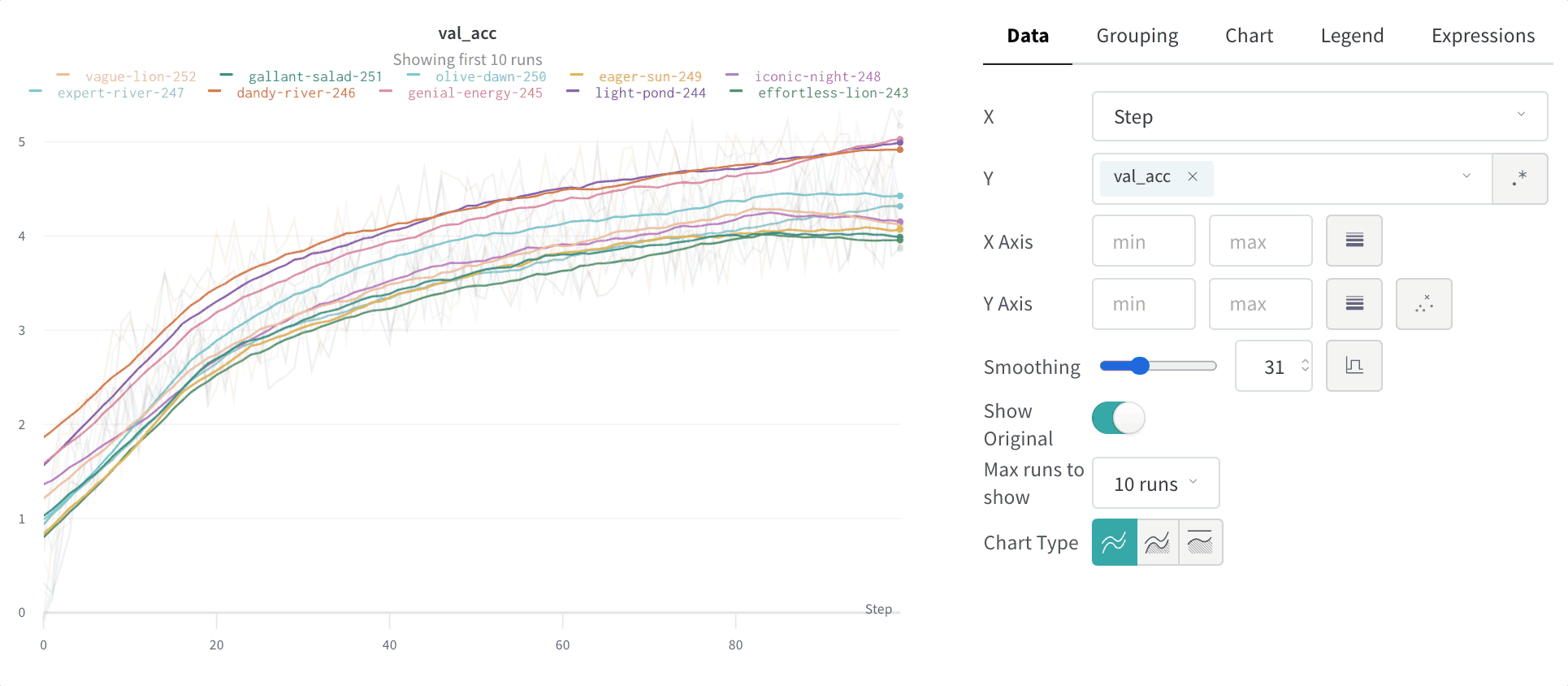
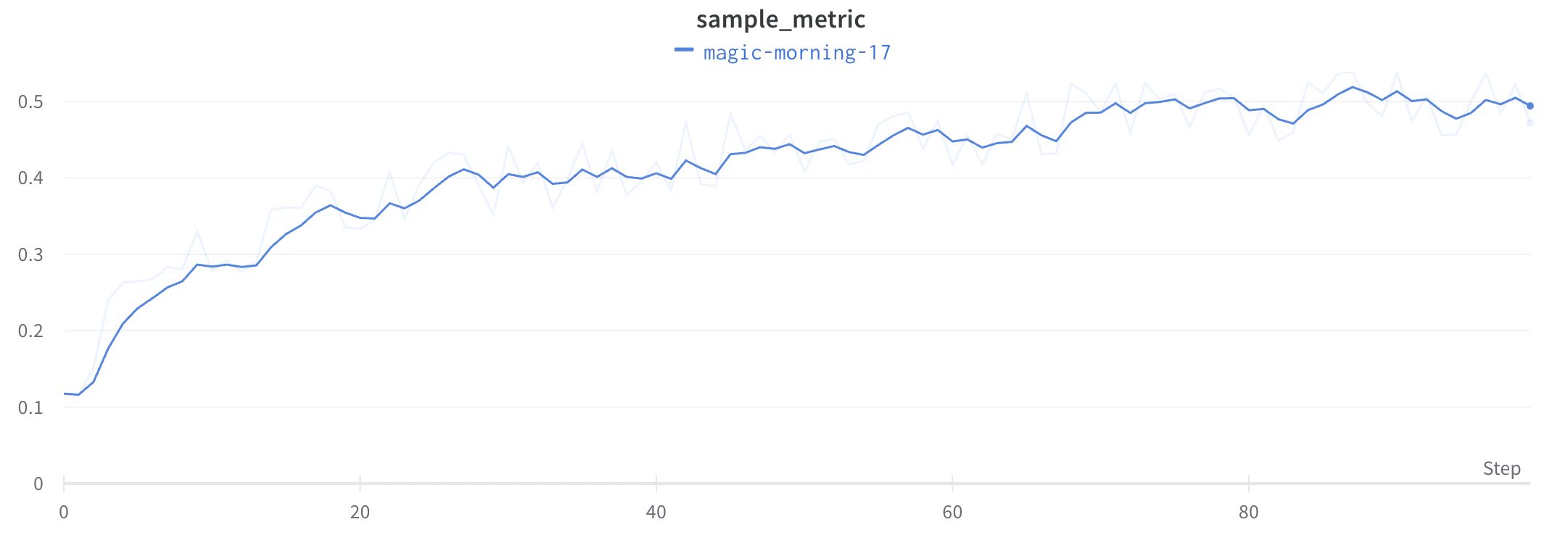
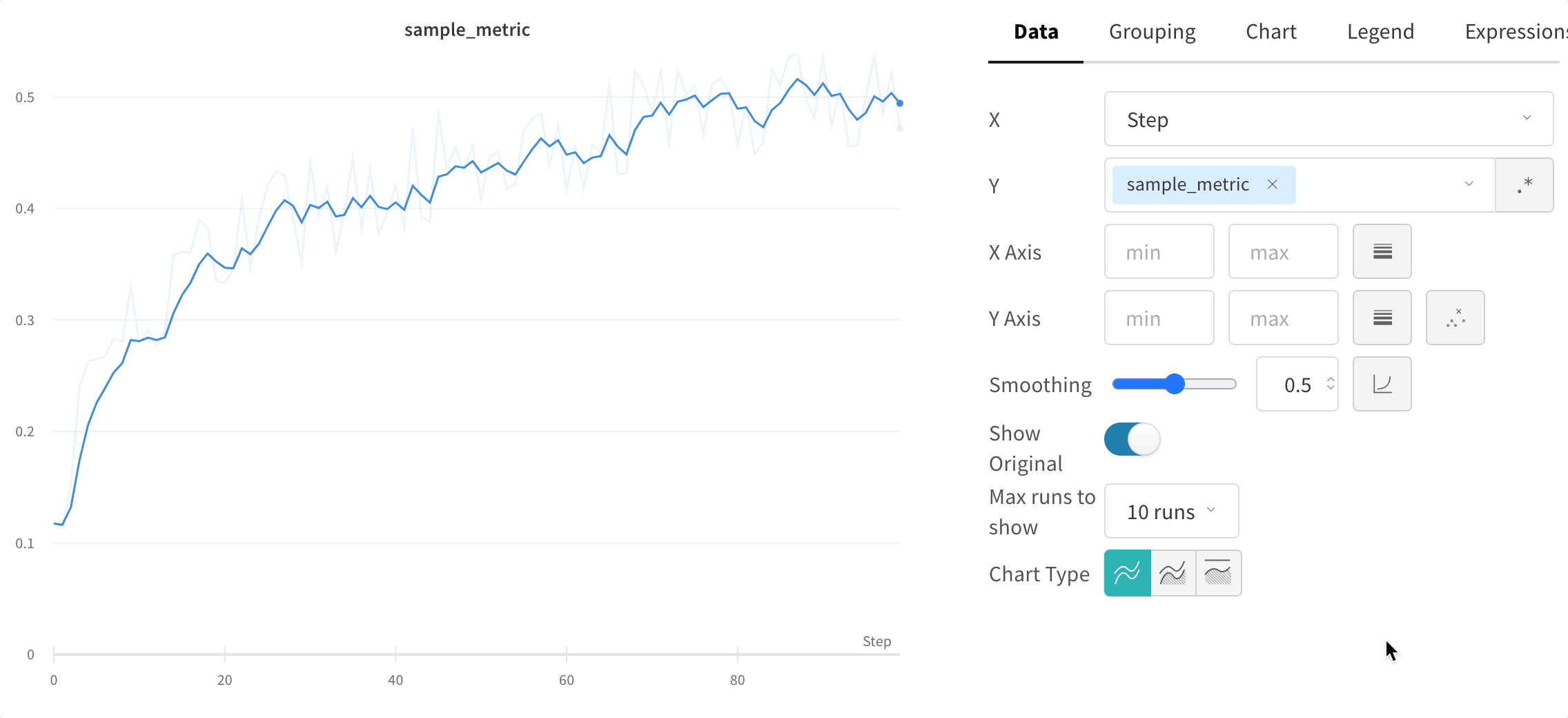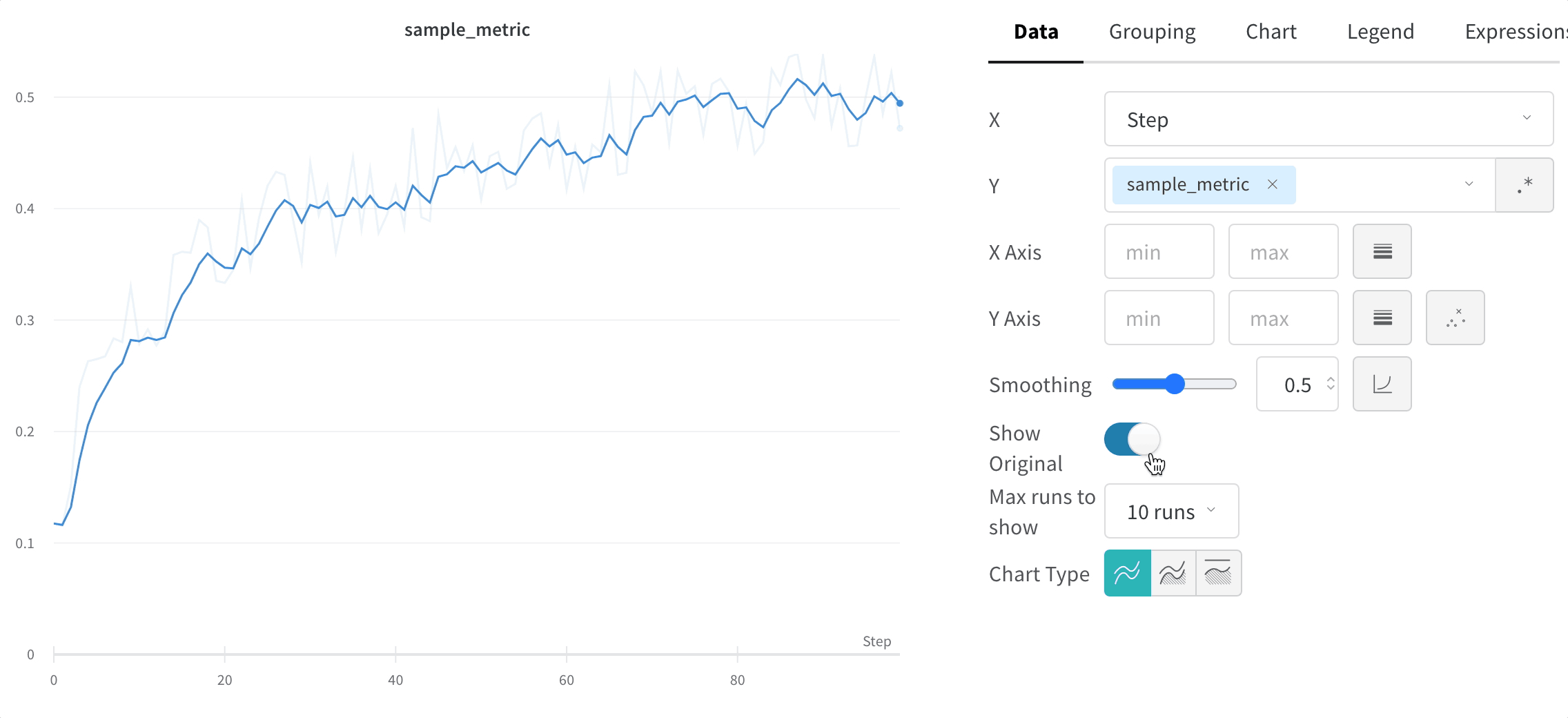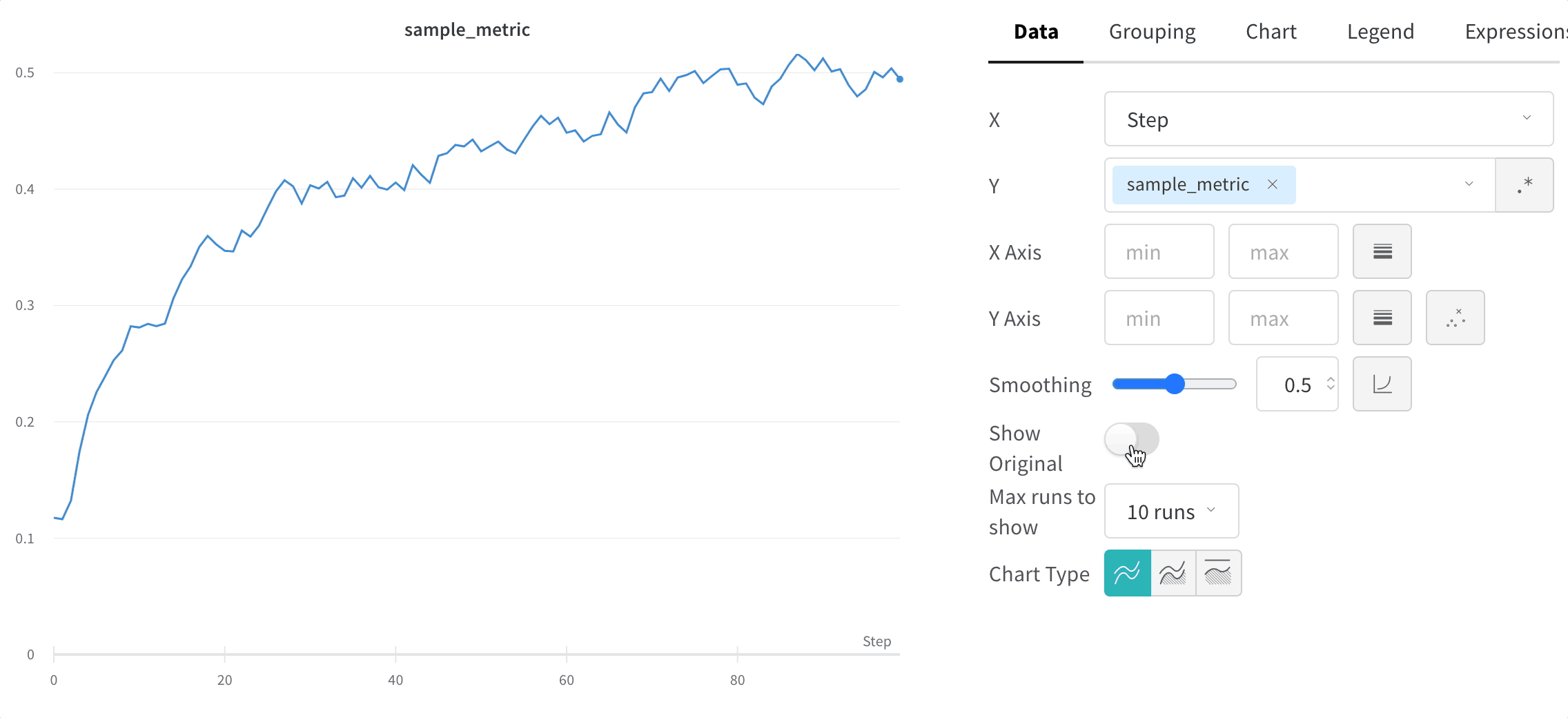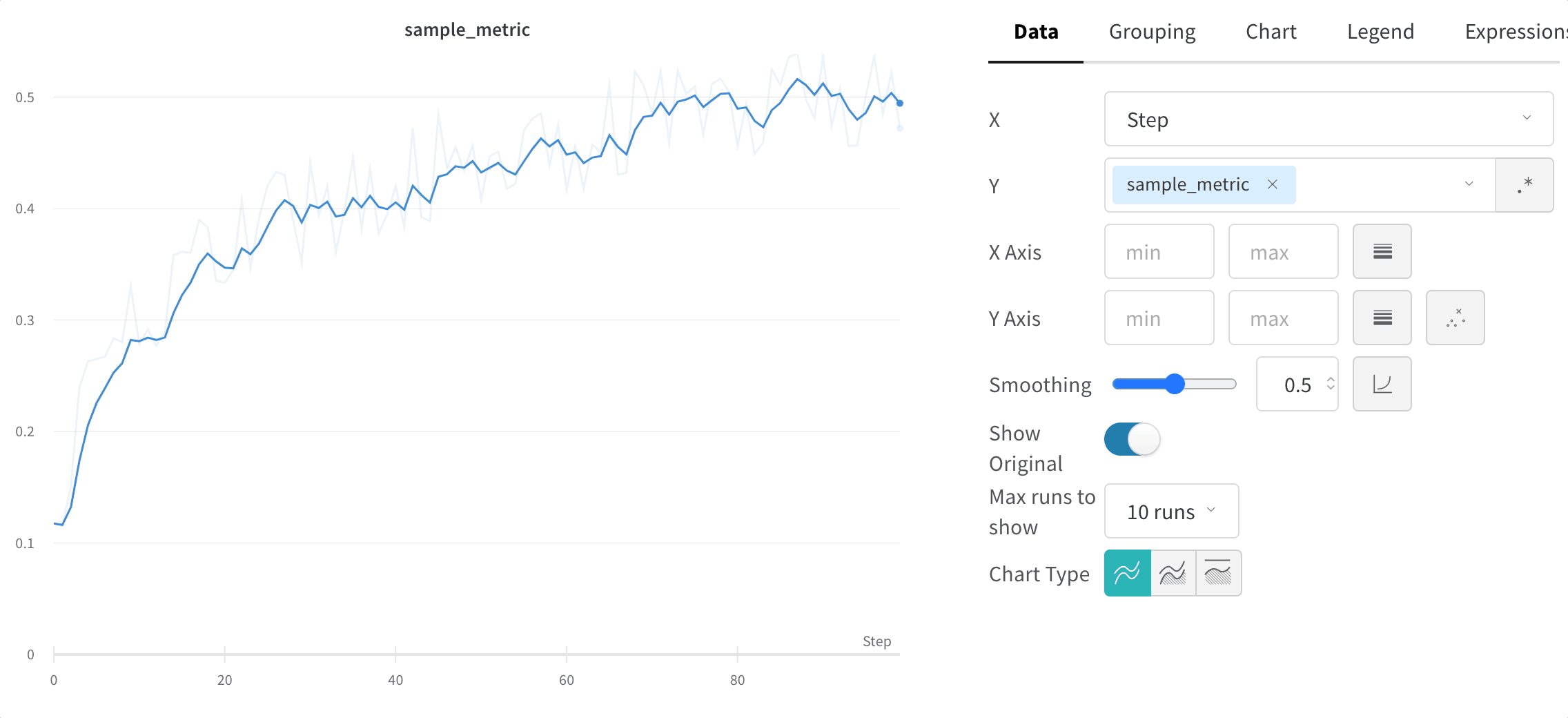
W&B prend en charge plusieurs types de lissage :
Voir ces méthodes en direct dans un rapport W&B interactif.
Lissage par moyenne mobile exponentielle pondérée dans le temps (TWEMA) (par défaut)
y par unité de plage sur l’axe x). Cela permet d’obtenir un lissage cohérent lors de l’affichage simultané de plusieurs lignes aux caractéristiques différentes.
Voici un exemple de code montrant comment cela fonctionne en arrière-plan :
const smoothingWeight = Math.min(Math.sqrt(smoothingParam || 0), 0.999);
let lastY = yValues.length > 0 ? 0 : NaN;
let debiasWeight = 0;
return yValues.map((yPoint, index) => {
const prevX = index > 0 ? index - 1 : 0;
// VIEWPORT_SCALE met le résultat à l'échelle de la plage de l'axe x du chart
const changeInX =
((xValues[index] - xValues[prevX]) / rangeOfX) * VIEWPORT_SCALE;
const smoothingWeightAdj = Math.pow(smoothingWeight, changeInX);
lastY = lastY * smoothingWeightAdj + yPoint;
debiasWeight = debiasWeight * smoothingWeightAdj + 1;
return lastY / debiasWeight;
});
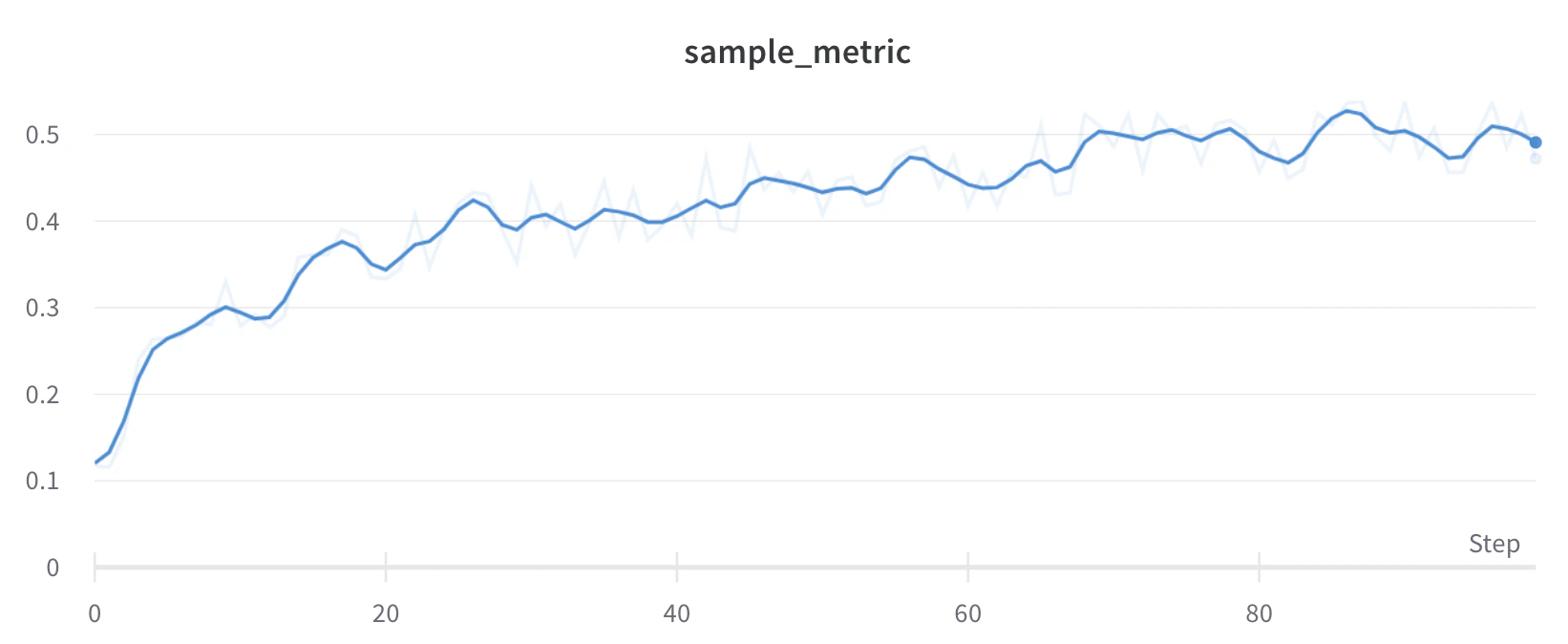
Lissage par moyenne mobile
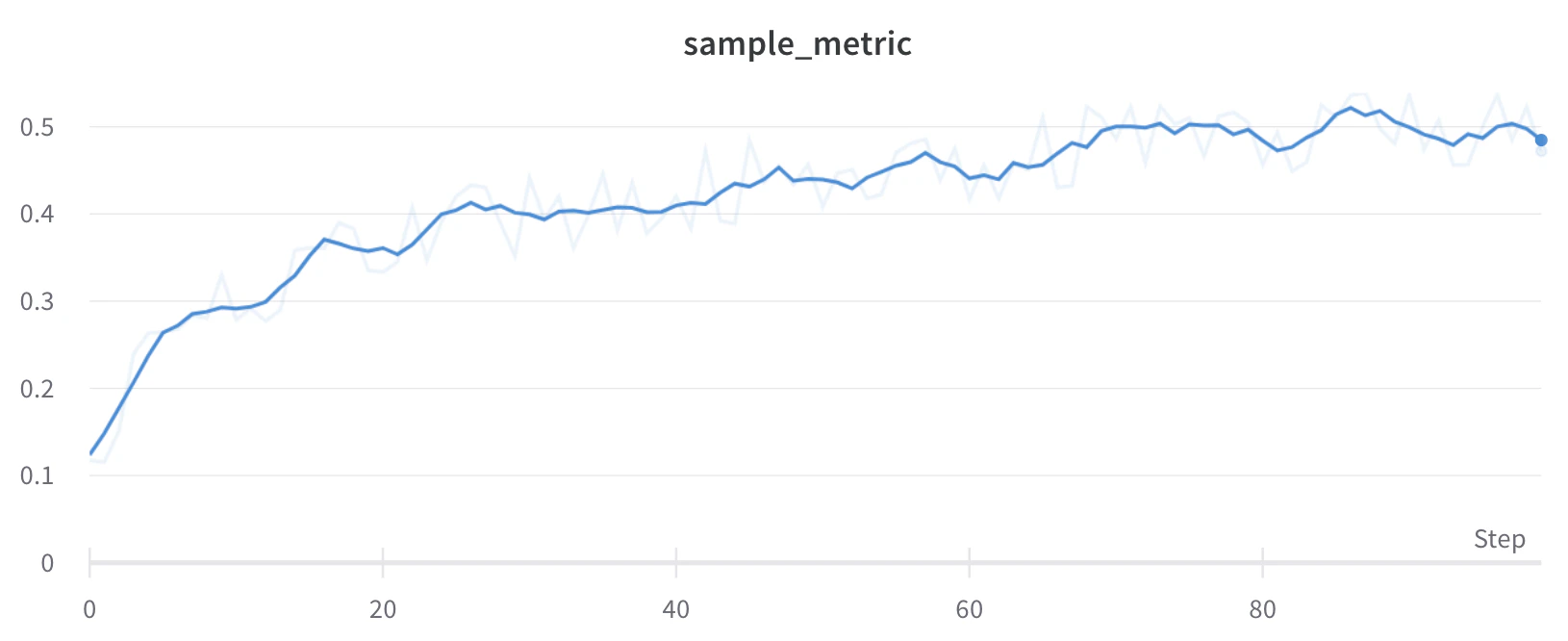
Lissage par moyenne mobile exponentielle (EMA)
- Échantillonnage
- Regroupement
- Expressions
- Axes x non monotones
- Axes x basés sur le temps
Voici un exemple de code montrant comment cela fonctionne en arrière-plan :
data.forEach(d => {
const nextVal = d;
last = last * smoothingWeight + (1 - smoothingWeight) * nextVal;
numAccum++;
debiasWeight = 1.0 - Math.pow(smoothingWeight, numAccum);
smoothedData.push(last / debiasWeight);
Masquer les données d’origine