Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-john-wbdocs-2044-rename-serverless-products.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Weave は、Cerebras Cloud SDK 経由の LLM call を自動的にトラッキングしてログします。
LLM call のトラッキングは、デバッグやパフォーマンス監視に不可欠です。Weave は、Cerebras Cloud SDK のトレースを自動的に取得することで、これを可能にします。
以下は、Cerebras で Weave を使用する例です。
import os
import weave
from cerebras.cloud.sdk import Cerebras
# weaveプロジェクトを初期化する
weave.init("cerebras_speedster")
# Cerebras SDKを通常通り使用する
api_key = os.environ["CEREBRAS_API_KEY"]
model = "llama3.1-8b" # Cerebrasモデル
client = Cerebras(api_key=api_key)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "What's the fastest land animal?"}],
)
print(response.choices[0].message.content)
 Weave opsは、コードを自動でバージョン管理し、入力と出力を記録することで、実験の再現性と追跡性を高められる強力な手段です。以下は、Cerebras SDKでWeave opsを活用する方法の例です。
Weave opsは、コードを自動でバージョン管理し、入力と出力を記録することで、実験の再現性と追跡性を高められる強力な手段です。以下は、Cerebras SDKでWeave opsを活用する方法の例です。
import os
import weave
from cerebras.cloud.sdk import Cerebras
# Weave プロジェクトを初期化する
weave.init("cerebras_speedster")
client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"])
# Weave はこの関数の入力、出力、コードをトラッキングする
@weave.op
def animal_speedster(animal: str, model: str) -> str:
"Find out how fast an animal can run"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": f"How fast can a {animal} run?"}],
)
return response.choices[0].message.content
animal_speedster("cheetah", "llama3.1-8b")
animal_speedster("ostrich", "llama3.1-8b")
animal_speedster("human", "llama3.1-8b")
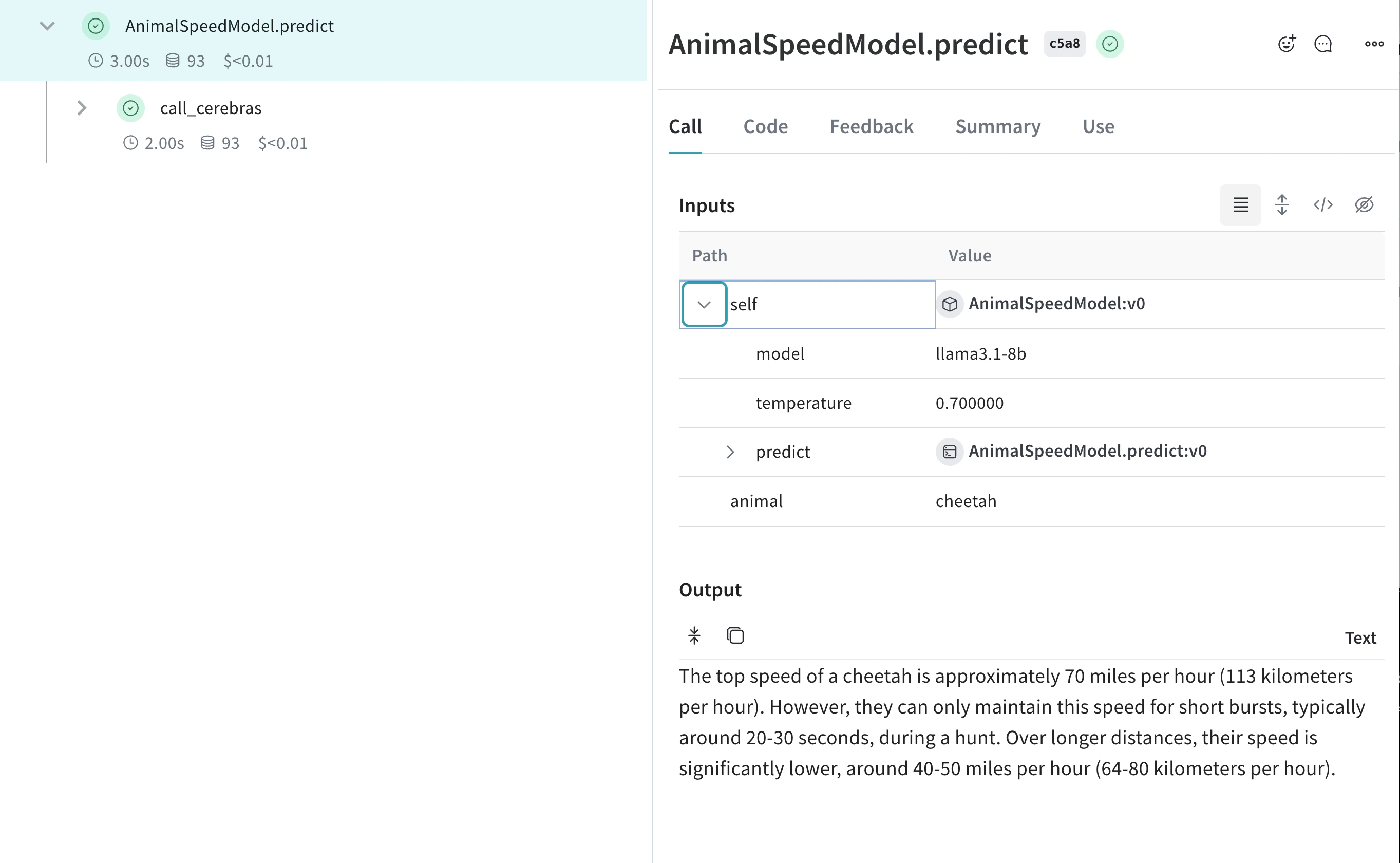
試行錯誤しやすくするために Model を作成する
import os
import weave
from cerebras.cloud.sdk import Cerebras
# weave プロジェクトを初期化する
weave.init("cerebras_speedster")
client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"])
class AnimalSpeedModel(weave.Model):
model: str
temperature: float
@weave.op
def predict(self, animal: str) -> str:
"動物の最高速度を予測する"
response = client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": f"What's the top speed of a {animal}?"}],
temperature=self.temperature
)
return response.choices[0].message.content
speed_model = AnimalSpeedModel(
model="llama3.1-8b",
temperature=0.7
)
result = speed_model.predict(animal="cheetah")
print(result)